Research Data Management - An Online Introduction
Bölüm anahatları
-
Publisher: HeFDI - Hessian Research Data Infrastructures
Authors (in alphabetical sequence): Arnela Balic (Frankfurt University of Applied Sciences), Muriel Imhof (Philipps-Universität Marburg), Sabrina Jordan (Universität Kassel), Esther Krähwinkel (Philipps-Universität Marburg), Patrick Langner (Hochschule Fulda), Andre Pietsch (Justus-Liebig-Universität Gießen), Robert Werth (Frankfurt University of Applied Sciences)
Acknowledgement: We would like to thank Stefanie Blum and Marion Elzner of Geisenheim University of Applied Sciences for their collaboration as well as the colleagues of the Thuringian Competence Network Research Data Management, the WG Prof. Goesmann "Bioinformatics and Systems Biology" (University of Giessen) and Dr. Reinhard Gerhold (University of Kassel) for their valuable feedback.
Last modified: 21.02.2025
Contact: forschungsdaten@fit.fra-uas.de -
Requirements: No previous knowledge is required for this learning module. The chapters are thematically based on one another, but can also be worked on individually. If information from other chapters is required, these are linked locally.
Target Audience: Students, doctoral candidates and researchers who are looking for a first introduction to research data management.
Learning Objective: After completing this chapter, you will be able to understand and implement the content and meaning of research data management. The learning objectives in detail are prefixed to the respective chapters.
Content: If you prefer reading, you can access only the content of this learning unit through the text. However, the inserted videos offer further access to the respective topic, so that those who work well with video explanations can see the content presented in a different way.
Average completion time (with videos): 3 hours 35 minutes
Average processing time (without videos): 2 hours 10 minutes
Licensing: This module is licensed under Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0). If you would like to repurpose the learning module, please feel free to write to hefdi@uni-marburg.de so that we can provide you with the latest version of the learning module.
Privacy (embedded videos): In this learning module, videos from YouTube are embedded on the following pages. When accessed, Google/YouTube uses cookies and other data, processes them and, if necessary, passes them on. Information about data protection and terms of use of the service can be found here. The use of the learning module requires appropriate consent.
-
Literature
Wilkinson, M. D. et al [2016]: The FAIR Guiding Principles for Scientific Data Management and Stewardship. In Scientific Data, 3, article 160018. https://doi.org/10.1038/sdata.2016.18 The original article on the FAIR principles, which have become probably the most important tool in the field of research data management for assessing the goodness of research data. They are part of the absolute basic knowledge in the field of research data management. All major funders require projects to ensure that the data generated in these projects comply with the FAIR principles. The FAIR principles are also an important part of the guidelines of the DFG code mentioned above. If there is no time to read the article, the FAIR principles can also be found on the pages of GO FAIR.
Open educational resources
Playlist of educational videos regarding research data management from RWTH Aachen An introductory video series on research data management at RWTH Aachen University in German and English, based on a specific fictional research project.
Websites
Council for Information Infrastructures (RfII) The Council for Information Infrastructures (Ger: Rat für Infomationsinfrastrukturen; RfII) is a committee of experts appointed by the Joint Science Conference (Ger: Gemeinsame Wissenschaftskonferenz; GWK), which regularly publishes reports, recommendations and position papers and, as an expert committee, also advises politicians and scientists on strategic issues relating to the future of digital science. For those who understand German, we particularly recommend the weekly mail service with up-to-date information on the topic of "research data management".
European Open Science Cloud (EOSC) The goal of the European Open Science Cloud (EOSC) is to provide European researchers, innovators, businesses, and citizens with a federated and open multidisciplinary environment in which they can publish, find, and reuse data, tools, and services for research, innovation, and education purposes. The EOSC is recognized by the Council of the European Union as a pilot project to deepen the new European Research Area (EFR). It is also referred to as the Science, Research and Innovation Data Space, which will be fully linked to the other sectoral data spaces defined in the European Data Strategy. The website linked here is the metaportal of the European Union, which aims to bundle the European services for making research data available.
forschungsdaten.info
Information portal for research data management focussing on German particularities. For an international perspective, see e.g. the UK Data Service’s Learning Hub (https://ukdataservice.ac.uk/learning-hub/).Hessian Research Data Infrastructures (HeFDI)
HeFDI is the Hessian state initiative for the development of research data infrastructures, in which all Hessian universities are involved. The state initiative intends to initiate and coordinate the necessary organisational and technological processes to anchor research data management at the participating universities. This includes not only a technical offering, e.g. in the form of a repository, but also counselling and other services such as regular training courses.Local Research Data Management Service Provider at Frankfurt University of Applied Sciences
This is the website of the central service centre for research data management at Frankfurt University of Applied Sciences (Frankfurt UAS). Here you will find the contact information of the research data team as well as FAQs on the topic of "research data management", which will hopefully answer some of your questions about research data management.National Research Data Infrastructure Germany (NFDI) The National Research Data Infrastructure (NFDI) is the largest German research data infrastructure project which intends to promote the development of a data culture and infrastructure based on the FAIR principles via the so-called NFDI consortia (associations of different institutions within a research field) in order to systematically open up and network valuable data stocks from science and research for the entire German science system to make them usable in a sustainable and qualitative manner.
Research Data Alliance (RDA) The Research Data Alliance (RDA) was launched in 2013 as a community-driven initiative by the European Commission, the National Science Foundation, and the U.S. Government's National Institute of Standards and Technology, and the Australian Government's Department of Innovation, with the goal of building a social and technical infrastructure that enables the open sharing and reuse of data. The RDA takes a grassroots, integrative approach that covers all phases of the data lifecycle, involves data producers, users, and managers, and addresses data sharing, processing, and storage. It has succeeded in creating a neutral social platform where international research data experts meet to exchange ideas and agree on topics such as social barriers to data sharing, education and training challenges, data management plans and certification of data repositories, disciplinary and interdisciplinary interoperability, and technological issues.
-








1.1: Stress, stress go away. Derivative version of: Stress lass nach – Eine Bildergeschichte zum Forschungsdatenmanagement. Created by Julia Werthmüller and Tatjana Jesserich, project FOKUS (Forschungsdatenkurse für Graduierte und Studierte), 2019. CC BY-SA 4.0 Funded by BMBF 2017-2019.
Source: Becker, Henrike, Einwächter, Sophie, Klein, Benedikt, Krähwinkel, Esther, Mehl, Sebastian, Müller, Janine, Werthmüller, Julia. (2019). Lernmodul Forschungsdatenmanagement auf einen Blick – eine Online-Einführung. Zenodo. https://doi.org/10.5281/zenodo.3381956
-
processing time: 15 minutes, 36 seconds
-
1.2 What is research data and what is research data management?
According to the "Guidelines on the Handling of Research Data" published by the DFG (German Research Foundation) in 2015, research data includes “among other things: Measurement data, laboratory values, audiovisual information, texts, survey data, objects from collections or samples that are created, developed or evaluated in scientific work. Methodological testing procedures such as questionnaires, software and simulations can also represent central results of scientific research and should therefore also be included under the term research data.”
Research data can therefore vary a lot depending on the subject area and doesn't only play a role in the typical disciplines that deal with data, such as the natural sciences or social and economic sciences (see Fig. 1.2 & Fig. 1.3), but also includes, for example, linguistic language data or image descriptions from the art sciences, etc.
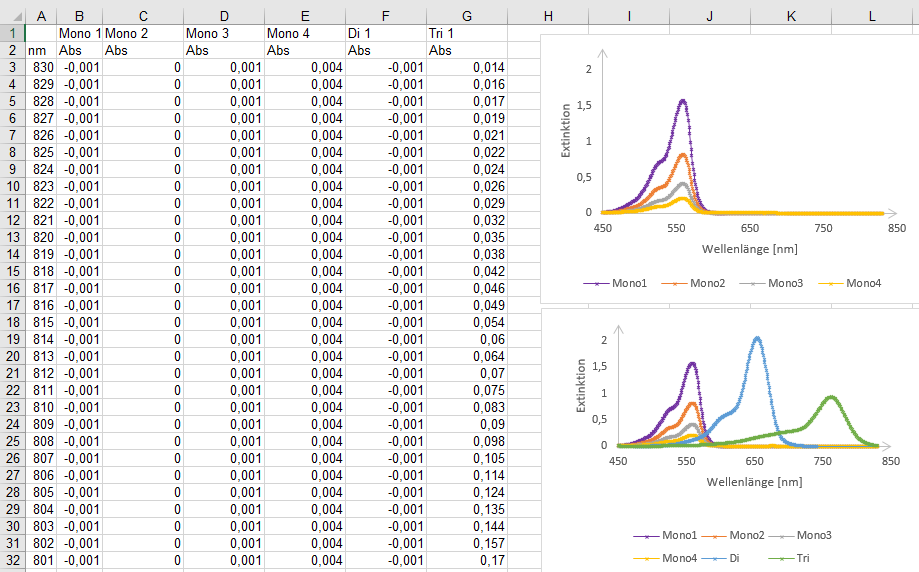 Fig. 1.2: Research data from chemistryFig. 1.3: Research data from economic sciences
Fig. 1.2: Research data from chemistryFig. 1.3: Research data from economic sciences
The focus is primarily on handling digital research data. The particular challenge is that, due to the digitalisation and automation of work processes, ever larger and heterogeneous amounts of data are being created, the sensible and coordinated handling of which is very time-consuming. This heterogeneity is characterised on the one hand by file formats that are used in many different ways (.txt, .docx, .pdf, .ods, etc.) and on the other hand by different forms of presentation with different levels of abstraction (graphics, 3D models, simulations, survey data, etc.).
Conventional scientific procedures often do not yet guarantee sufficient use of the large amounts of data. Furthermore, there are still only a few overarching standards for handling (digital) research data. Handling is mainly shaped by individual or subject-specific practices. Data loss or the non-reproducibility of data are not uncommon, especially after project completion. Research data can then only be reused or reproduced for further research purposes to a limited extent, for example, due to a lack of documentation of the work steps or outdated formats (cf. Büttner, Hobohm and Müller 2011: 13 et seq.).
It is precisely this problem that research data management addresses. It is intended to offer sustainable opportunities for the handling of research data. Research data management, or RDM for short, encompasses the entire handling of research data, from planning, collection, processing, and quality assurance to storage and making available or publication. All steps of RDM should be documented and aligned with the current subject-specific standards and practices of the individual scientific disciplines. Many scientific institutions have now published a research data guideline to regulate the handling of research data as a first step. The research data guideline of the Frankfurt UAS can be found here.
-
1.3 Advantages of good research data management
But what advantages do you actually get from good research data management (RDM)? In a first step, Figure 1.4 breaks down the various goals that can be pursued through RDM for different dimensions.
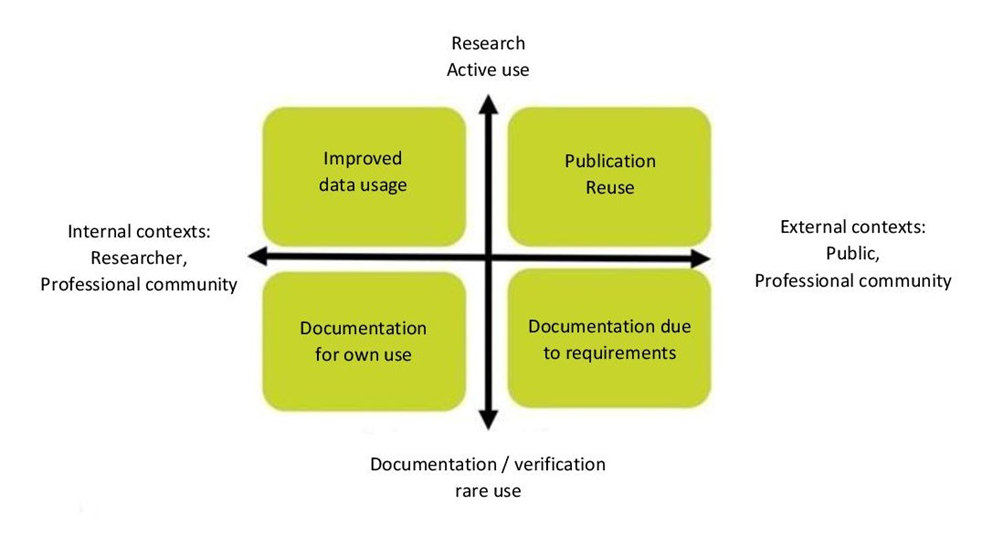 [Image: Jens Ludwig, what are research data? Nestor PERICLES School 2016]
[Image: Jens Ludwig, what are research data? Nestor PERICLES School 2016]Fig. 1.4: Goals of the RDM for different dimensions
The goals are influenced by different dimensions (internal/external context; active/rare use of data). Research data management should support researchers in the handling and traceability of their data (the two left boxes) and meet the demands of the public (the two right blocks). Furthermore, it should ensure that generated data can be actively used for further research (upper blocks), as well as for long-term quality assurance in the form of documentation of the research process (lower blocks) (cf. Broschard and Wellenkamp 2019: section Benefits of research data management).Research data management should lead to long-term traceability and reproducibility of data through appropriate documentation of the research process and minimise data loss. The transparency of data collection and processing is thus promoted and validation of research results, e.g., in case of allegations, is further facilitated. In the long run, successful research data management saves time and resources. Reasons for this include better collaboration (e.g. through common standards, use of common platforms, etc.), avoidance of errors and protection against data loss.
In addition to these practical benefits during research, a publication of well-documented and reusable datasets improves visibility and reputation for you as a researcher, as increasingly not only scientific articles but also data publications are appreciated with ever increasing tendency.
-
-
-
processing time: 9 minutes, 45 seconds
-
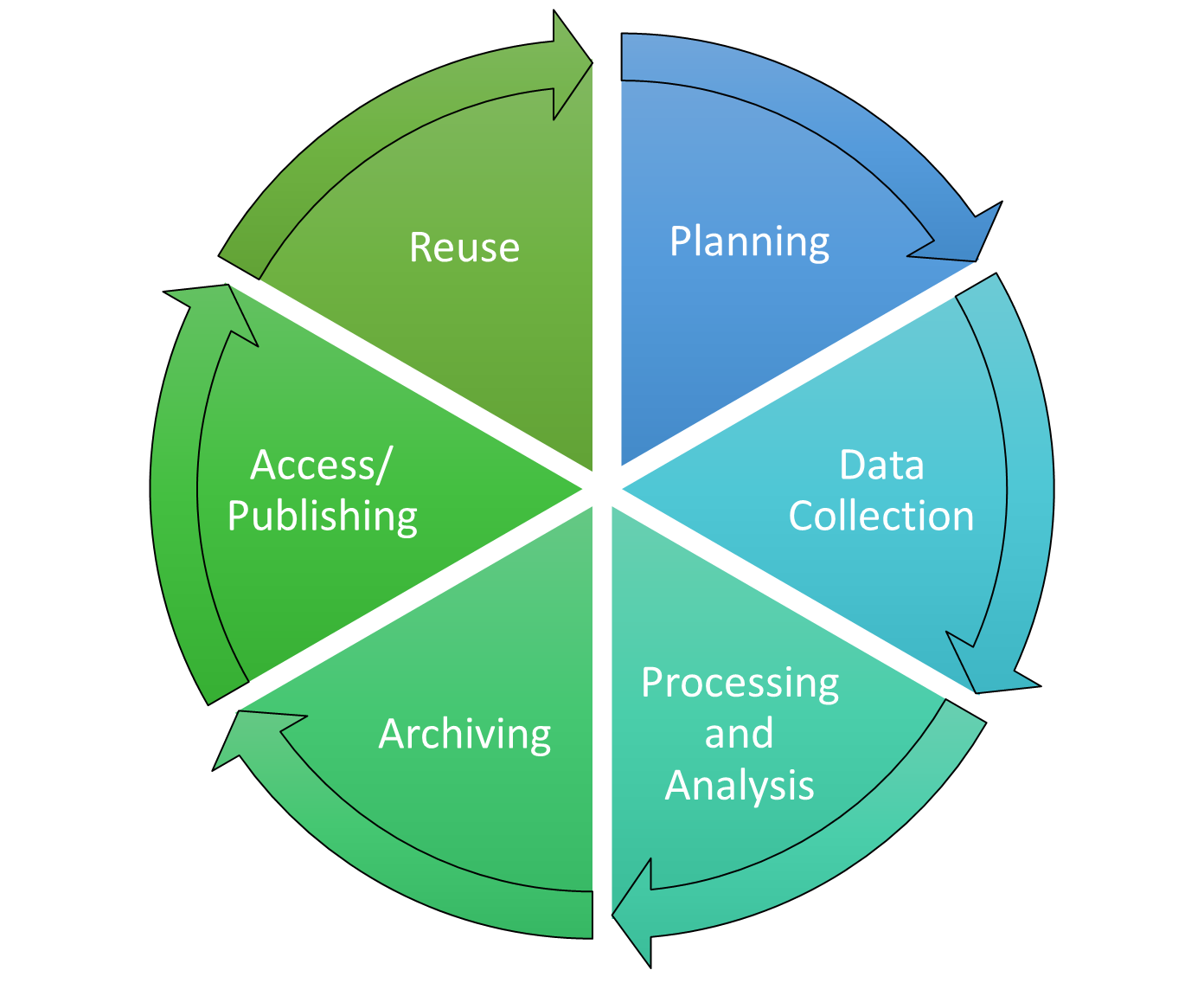
2.2 The research data life cycle
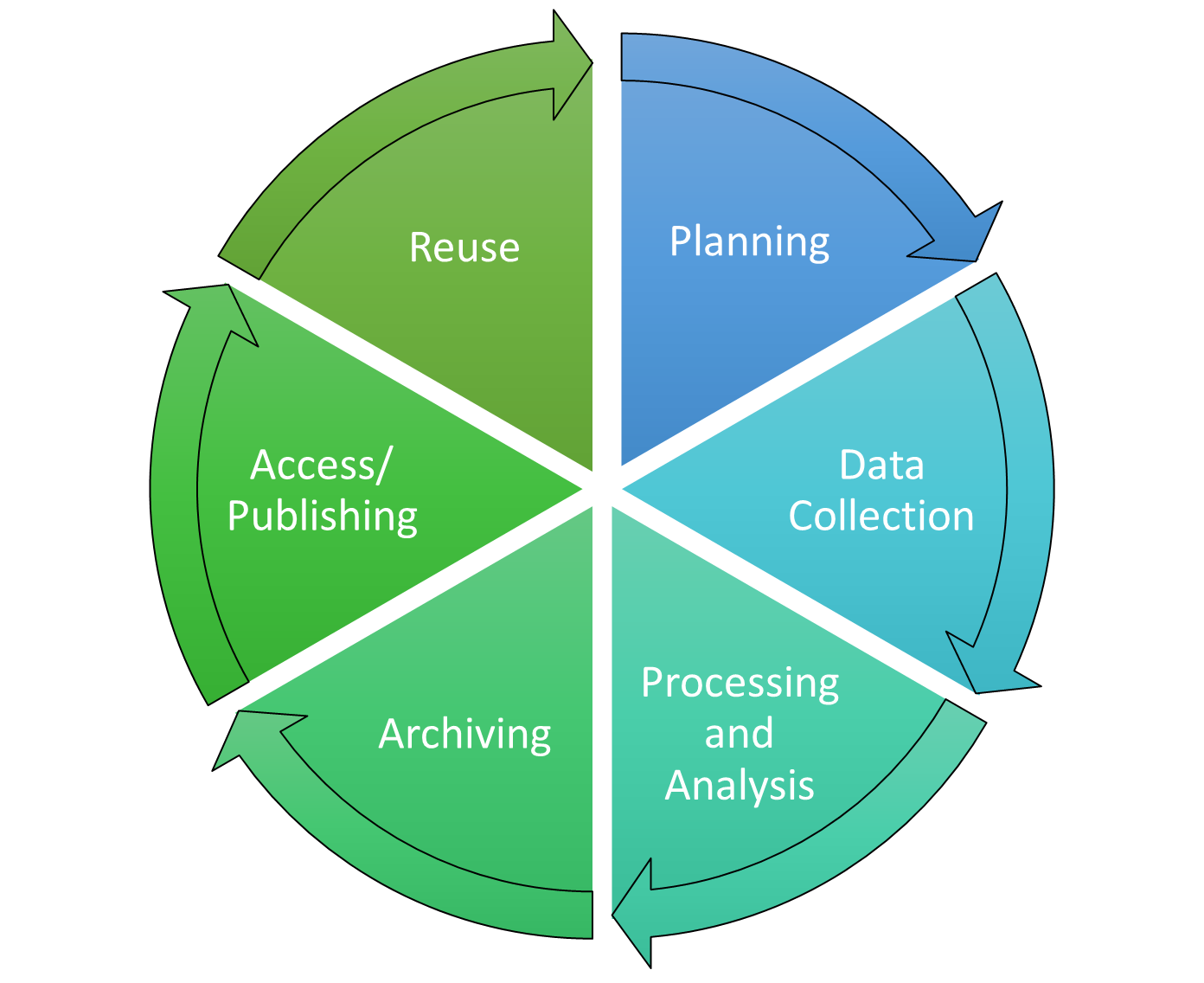
Fig. 2.1: The research data lifecycle (based on the DCC Curation Lifecycle Model)
The research data life cycle is a visualisation of the research process that focuses specifically on the role of data. It shows that a professional approach to research data involves more than just collection and analysis. As a researcher, it is worthwhile to always consider all phases when making decisions and to find out at an early stage which tools and options are available to optimise your practice in dealing with research data.
-
2.3 Individual steps in the research data life cycle
The following section takes a closer look at the individual phases and describes what you can do in detail with regard to research data management.
1. Planning
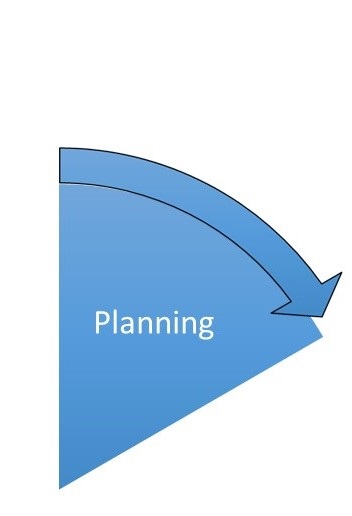
“By failing to plan, you are preparing to fail.” - Benjamin Franklin
Only with good planning good results can be achieved. This requires careful consideration, consultation, and research. With regard to research data management, many research funders already require a so-called data management plan when the application is submitted (see Chapter 3). However, even without explicit requirements, it is worthwhile to set out in writing in advance exactly how the data are to be handled. This creates commitment and uniformity (especially in projects with several participants) and can serve as a reference work, checklist, and documentation.
Overall, the following aspects may be relevant for planning:
- Determine study design
- Assemble project team and clarify roles
- Set up schedule
- Plan data management (formats, storage locations, file naming, collaborative platforms, etc.)
- Review existing literature and data
- Re-use of existing data, if applicable
- Clarify authorship and data ownership
- Coordinate access possibilities and conditions
2. Survey
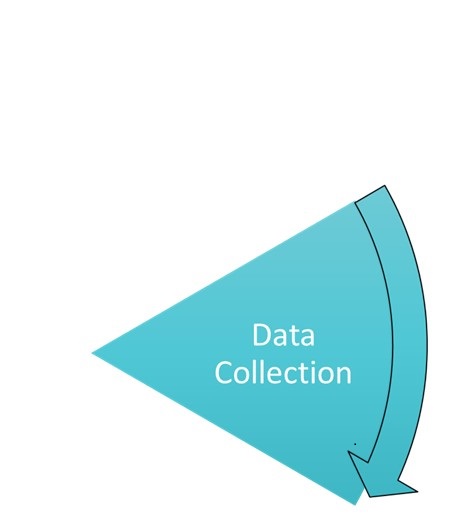
Data collection can sometimes account for a considerable part of the research work. In addition, mistakes made in this phase persist throughout the entire research process and, in the worst case, lead to incorrect results without being noticed. This makes it all the more important to take special care during the survey. In addition to the actual data, this concerns above all the documentation of the research carried out as well as a (preferably standardised) collection of metadata. Metadata has to be well structured and offers further information about your data, which is described in more detail in Chapter 4.
Overall, the data collection should cover the following aspects:
- Carrying out the experiments, observations, measurements, simulations, etc.
- Generation of digital raw data (e.g. by digitising or transcribing)
- Storage of the data in a uniform format
- Backup and management of data
- Metadata collection and creation
- Documentation of the data collection
3. Processing / Analysis
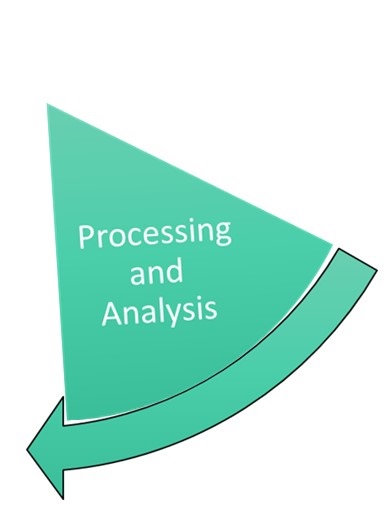
You know best how to analyse your data. It is important that you apply and document the standards and methods that are common in your field.
For yourself and especially in collaboration with others, it is important to have a system of file naming, versioning, and data organisation. Collaboration platforms offer support. For more information, see Chapters 6 and 7.
Overall, you can consider the following aspects when processing and analysing data:
- Check, validate, clean data (quality assurance)
- Derive, aggregate, harmonise data
- Use subject-specific standards (e.g. with regard to methods and file formats)
- Prepare the use of the data in scientific publications
- Document data processing (for later understanding)
- Use cooperation platforms for data exchange with (specialist) colleagues
- Run analyses
- Interpret data
4. Archiving
In the Code for “Safeguarding Good Research Practice” (2019) of the German Research Foundation, guideline 17 describes that “research data (generally raw data) […] are generally archived in an accessible an identifiable manner for a period of ten years”. This serves scientific quality assurance and enables the long-term verifiability of scientific findings. In addition, the data can be reused by other scientists if necessary.
However, in order to enable actual reuse, a number of conditions must be met:
- Comprehensibility
- Durable, preferably non-proprietary (i.e. free and open source) file formats.
- durable storage media
- Findability
It therefore makes sense to use professional archiving services. The Frankfurt UAS offers the following (free) service for this purpose: Institutional Research Data Repository
You will learn what else you should consider with regard to archiving your research data in Chapter 8.
5. Access / Publication
In addition to (text) publication in scientific journals, the data on which publications are based are also increasingly in demand. Many research funders and journals now require explicit data publication. This can provide additional quality assurance and, if other researchers work with your data, you gain reputation through citations.
There are basically three ways of publishing research data (Biernacka et al., 2018):
- As a supplement to a scientific article (= data supplement)
- As an independent publication in a repository (= long-term storage location for data)
- As an article in a Data Journal
a. These are (usually) peer-reviewed papers that present and describe datasets with a high value for reuse in more detail. The data itself is usually published in a research data repository.
The portal re3data is suitable for searching for an appropriate repository. Its important that the chosen repository meets the FAIR principles for research data. Further information on this can be found in Chapter 5.
6. Subsequent use
When sharing and publishing research data, make sure that it can actually be re-used. This opens up a wide range of possibilities:
- Further research with existing data (secondary data analysis)
- Verification of results (replication, quality assurance)
- Linkage with other data (record linkage)
- Use in practical teaching
The prerequisite for subsequent use is licensing. Creative Commons licences are often used for this. In the spirit of Open Science, these should be chosen as openly as possible.
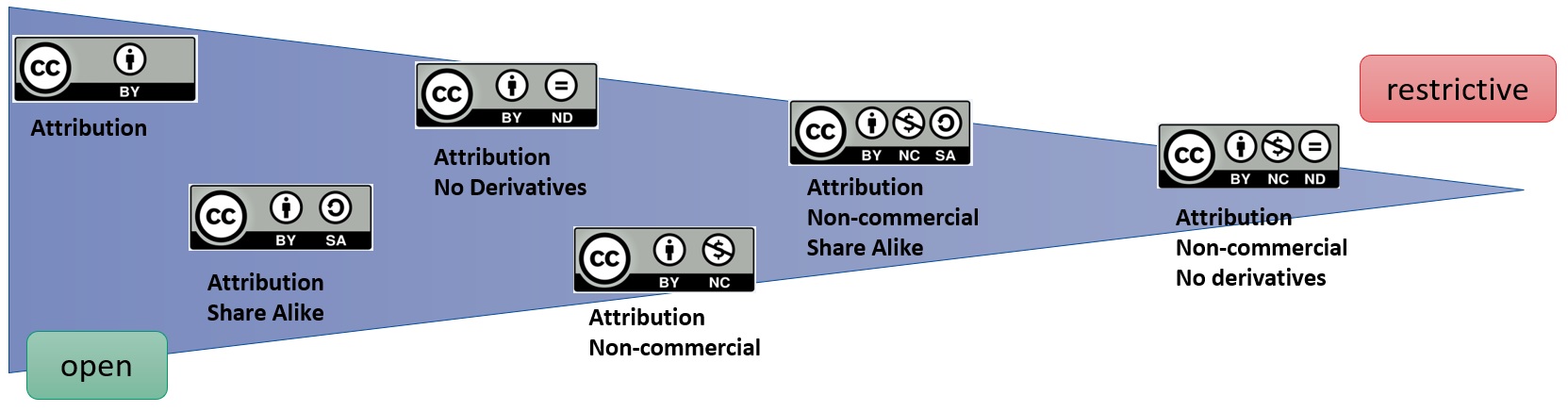
Fig. 2.2. Possible uses of data under different Creative Commons licences (Translated from: Apel et al. 2017, p. 57)
Furthermore, it is important that the data is of good quality (complete, accurate, cleaned, without gaps) and sufficiently documented. File formats also play an important role. These should be as widespread and non-proprietary as possible. If necessary, it may also make sense to store the data twice (once in the original format and once in an open format). An overview of suitable file for-mats can be found, for example, at forschungsdaten.info.
To ensure that data can be found and cited correctly in the long term, the use of persistent identifiers (PID) is a good idea. They permanently refer to a specific content (e. g. data set) and are thus ideally suited for citations. A web link can change, a PID always remains the same. There are two types of PIDs:
- Identifiers for digital objects, e.g.
- DOI = Digital Object Identifier
- URN = Uniform Resource Name
- Identifier for persons (clear scientific identity), e.g.
- ORCID = Open Researcher Contributor Identification
- ResearcherID
Repositories and journals automatically assign corresponding identifiers for the data/contributions submitted. If you also have a personal identifier (such as ORCID), your work can be automatically linked to your profile.
-
-
-
processing time: 11 minutes, 12 seconds
processing time (without video): 5 minutes, 53 seconds -
Bearbeitungsdauer: 24 Minuten, 12 Sekunden
-
4.3 What do metadata look like?
Metadata always have a certain internal structure, even though the actual application can take different forms (e.g. from a simple text document to a table form to a very formalised form as an XML file that follows a certain metadata standard). The structure itself depends on the described data (for example, use of headers and legends in Excel spreadsheets versus a formalised description of a literary work in an OPAC), the intended use and the standards used. Generally speaking, metadata describe (digital) objects in a formalised and structured way. Such digital objects also include research data. In our application, metadata describe your own research project and related research data in a formalised and structured way.
It makes sense, but is not absolutely necessary, for metadata to be readable not only by humans, but also by machines, so that research data can be processed by machines and automatically. Machines are primarily computers in this case, which is why one can also speak more precisely of readability for a computer. To achieve this, the metadata must be available in a machine-readable markup language. Research-specific standards in the markup language XML (Extensible Markup Language) are often used for this, but there are also others such as JSON (JavaScript Object Notation). When submitting (research data) publications, in most cases there is the option of entering the metadata directly into a prefabricated online form. A detailed knowledge of XML, JSON or other markup languages is therefore not necessarily required when creating metadata for your own project, but it can contribute to understanding how the research data is processed.
Computer readability is an essential point and becomes important, for example, when related research data are to be found by keyword search or compared with each other. A machine-readable file can be created using special programmes. In the section “How do I create my metadata” you will be introduced to appropriate programmes.
If you are not familiar with the creation of machine-readable metadata files, you should save the metadata for your research data in a form that you can create. For example, a simple text file can be created using the integrated editor of your operating system, in which each line contains information. When doing so, consider which information is important for traceability (e.g. creator of the data, date of creation/experiment, structure of individual experimental set-ups, etc.). The categories depend on the type, scope and structure of the research data. A transfer into a machine-readable form is still possible with proper and comprehensible documentation at the end of a project or a section of the project.
Examples of metadata
In the following, a few examples will show what metadata can look like.
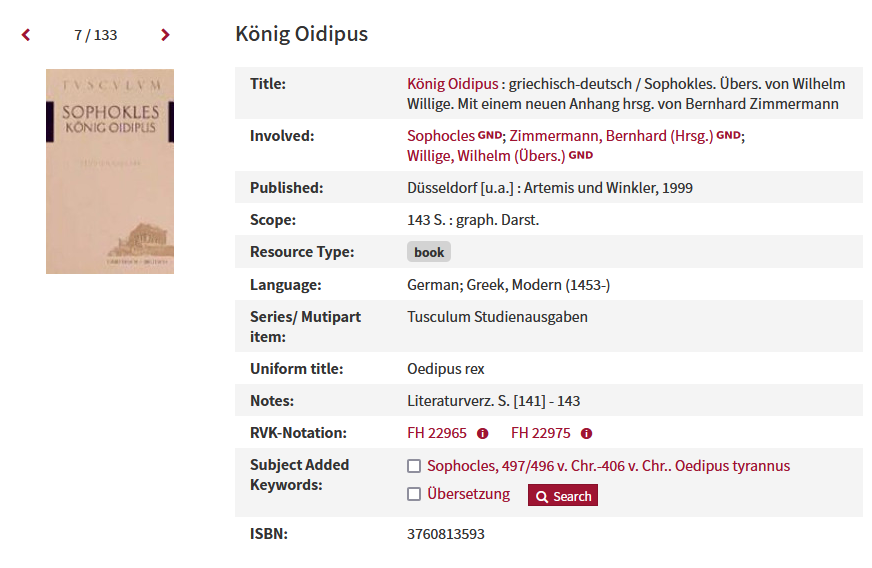
Fig. 4.1: Entry of a work in an online library catalogue (source: https://ubmr.hds.hebis.de/Record/HEB060886269?lng=en)
Figure 4.1 shows a book title as an entry in an online library catalogue in a form that you, as a member of a university, have probably seen many times before. It should be noted at this point that metadata is not a new development and does not only play a major role in the digital age, but has already been used before, for example, in the creation of card catalogues in libraries for locating books. The information listed in Figure 4.1 is also nothing more than metadata that can be processed by a processing system and read by users to obtain information about a particular book. They learn about the title, the author(s), the volume, the year of publication, the language, etc.
Although the data from the example above is probably very different from your research data, it illustrates very well the way metadata is collected. If metadata for research data were written in the way shown here, namely in a kind of two-column table, with one column containing the category (e.g. title) and another column containing the actual information (here “King Oedipus”), this information would in any case be helpful for a later researcher to understand the data. However, it would not yet lead to computer systems being able to process this data automatically.
If you have no experience at all with the creation of computer-readable metadata, it is worthwhile, as already mentioned, to use such a tabular list of all relevant data in a file (e.g. .docx, .xlsx, .txt, etc.) at the beginning of a research project and to keep it current, in order to have this data at hand for a possible later submission. Also stick to a sensible versioning concept in order to make changes in the data traceable in the course of the project (see Chapter 8).

Fig. 4.2: Machine-readable example metadata according to the Dublin Core Metadata Element Set (created by Henrike Becker in the project "Fokus")
Figure 4.2 shows part of a machine-readable metadata record written in the markup language XML according to the conventions of the Dublin Core Metadata Element Set, which was first published by the Dublin Core Metadata Initiative in 1995 (more on this in section 4.4 – “What are metadata standards?”). How this can be recognised is explained below.
Everything written in blue in Figure 4.2 are elements, everything written in black is the content of these elements. A simpler understanding of this relationship can be obtained by looking at Figure 4.1: The left column contains the type of information or category (e.g., “title”, “author”, etc.), the right column shows the actual information within this category (e.g., “King Oedipus”, “Sophocles”, etc.). The relationship between the element and the content of the element is analogous, with the type of information/category representing the elements (blue font in Figure 4.2) and the actual information representing the content of the elements (black font in Figure 4.2).
A fundamental difference, however, is the structure: element names are always enclosed in less-than and greater-than signs
<...>. In addition, there is an opening and a closing element for each category. The opening element can be recognised by the less-than sign<and always stands before the actual information. The closing element is recognisable by the forward slash/after the less-than sign<and always comes after the actual information of the respective category. These opening and closing elements thus practically always enclose the information content, which is easily recognisable in Figure 4.2. The information about the category is located between the the less-than and greater-than signs (e.g., “title”, “creator”). The information written in black between<dc:creator>and</dc:creator>thus gives information about the author of the respective document or data, for example. In the case of Figure 4.2, this would be “Henrike Becker”. At this point, the other elements shown in Figure 4.2 should be briefly explained. The<dc:title>element contains the title under which the document or research dataset was published. Systems that read and display titles from a database often use the content of this element as information.<dc:subject>can occur several times and always contains a subject of the content in keywords that serve as a search basis. The second<dc:subject>element in Figure 4.2 contains a very long specification of a subject (i.e. not only keywords), which should rather be avoided in order to achieve better search results. The<dc:description>element gives a short summary of the content. In the case of text publications, the table of contents can also be placed there. Multiple entries are also possible for this element.<dc:date>contains a date, usually the date of publication. If possible, the date should be written according to DIN ISO 8601 as YYYY-MM-DD for better findability. Within this element, sub-elements (so-called child elements) can be placed, which finally give more precise information about the date, such as whether it is the date of creation, the date of the last change or the date of publication. The<dc:identifier>element is only present once and mandatory in a metadata record. The persistent identifier it contains, is assigned only once worldwide and uniquely identifies the document or research dataset. More information on persistent identifiers can be found in the following section “Which categories are important” as well as in the section “Findable” of Chapter 5.The two letters with the colon
dc:that precede the actual element namecreatoretc. in the elements show that the elements come from the Dublin Core Metadata Element Set mentioned at the beginning. Further information on why these two letters should or often even have to be written in front of them is explained in more detail in section 4.4 – “What are metadata standards?”And now it's your turn. In the table shown, what is data and what is metadata? Click on the image to see the solution.

Fig. 4.3: Data and metadata of an Excel table
There are very many different categories that can and often must be described by metadata. Depending on the field and research data, these categories can differ greatly, but some are considered standard categories for all disciplines.
One category that should be present in the metadata at the latest in the case of a citable publication is the “persistent identifier” mentioned in the previous section. An identifier is used for permanent and unmistakable identification. The DOI (Digital Object Identifier) is well-known and frequently used. A DOI is assigned by official registries, such as DataCite. Metadata are linked to the document and the research data via a DOI. Research data can be cited via a DOI.
Furthermore, the metadata should indicate who the author of the data is. In the case of research groups, all those involved in the work or who may have rights to the research data should be named. The latter may, of course, include companies that may have contributed to the funding of the research. Always make sure that the names are complete and unambiguous. If a researcher ID (e.g. ORCID) is available, this should be mentioned.
The research topic should be described in as much detail as necessary. In view of the findability of the research data, it can also be useful to mention keywords that can then be used in a digital database search to achieve better results.
Furthermore, for the traceability of the research data, clear information is needed for parameters such as place / time / temperature / social setting, ... and any other conditions that make sense for the data. This also includes instruments and devices used with their exact configurations.
If specific software was used to create the research data, the name of the software must also be mentioned in the metadata. Of course, this also includes naming the software version used, as this makes it easier for researchers to understand later why this data can no longer be opened in the case of very old data.
Some metadata requirements are always the same. This also applies to the categories just listed, which are very generic. For such cases, there are subject-independent metadata standards, including the already introduced Dublin Core Element Set. Other requirements can differ greatly between different disciplines. Therefore, there are subject-specific standards that cover these requirements. You can read more about this in the next section 6.4 – “What are metadata standards?”.
Figure 4.4 shows different categories of metadata that may prove useful with regard to research data.
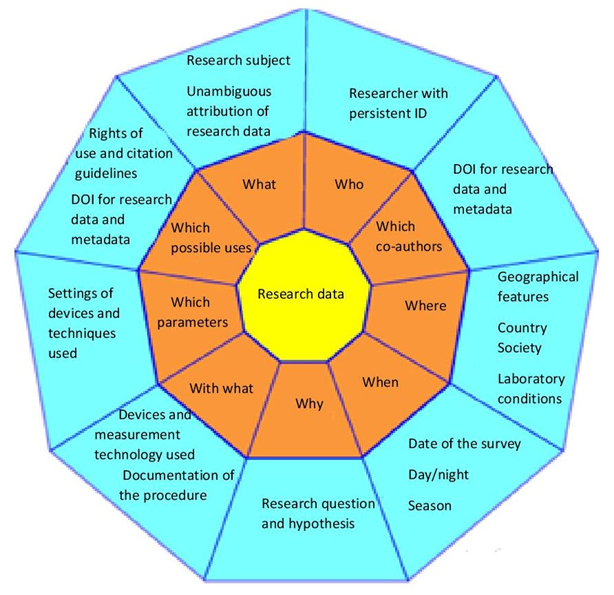
Fig. 4.4: Listing of sample categories (Created by Henrike Becker in the project "Fokus")
-
-
-
processing time: 14 minutes, 4 seconds
-
5.4 Possibilities of implementation
Implementing the FAIR principles in every aspect is a challenge. To have a first indicator of how FAIR your data is, you can use the FAIR self-assessment tool from the Australian Research Data Commons, which you find here. Furthermore, when selecting a data repository for storing and publishing your data, you can definitely make sure that it has a “FAIR Compliance” designation. To do so, it must meet the requirements listed here:
- The data sets (or ideally the individual files of a data set) are provided with unique and permanent persistent identifiers (e.g. DOIs).
- The database allows the upload of intrinsic metadata (e.g. name of the author, content of the dataset, associated publication) as well as metadata defined by the person responsible (e.g. names of variables).
- The licences (e.g., CC0, CC-BY, MIT) under which the data can be made available in the repository must be clearly identifiable or selectable by the user.
- The source information, including metadata, is always publicly available, even in the case of restricted-access datasets.
- The data archive provides an input screen that prescribes a specific format for the intrinsic metadata (to ensure machine readability/compatibility).
- The database has a plan for the long-term preservation of the archived data.
Source: Swiss National Science Foundation. Data Management Plan (DMP) – Guidelines for researchers
When searching for a suitable repository that meets the FAIR data principles, you can also use the Repository Finder. If you activate the option “See the repositories in re3data that meet the criteria of the FAIRsFAIR Project”, you will get an overview of certified repositories that offer Open Access and persistent identifiers for the data. The Repository Finder uses the Registry of Research Data Repositories (re3data) for the search. It provides a good overview of international research data repositories in a variety of scientific disciplines.
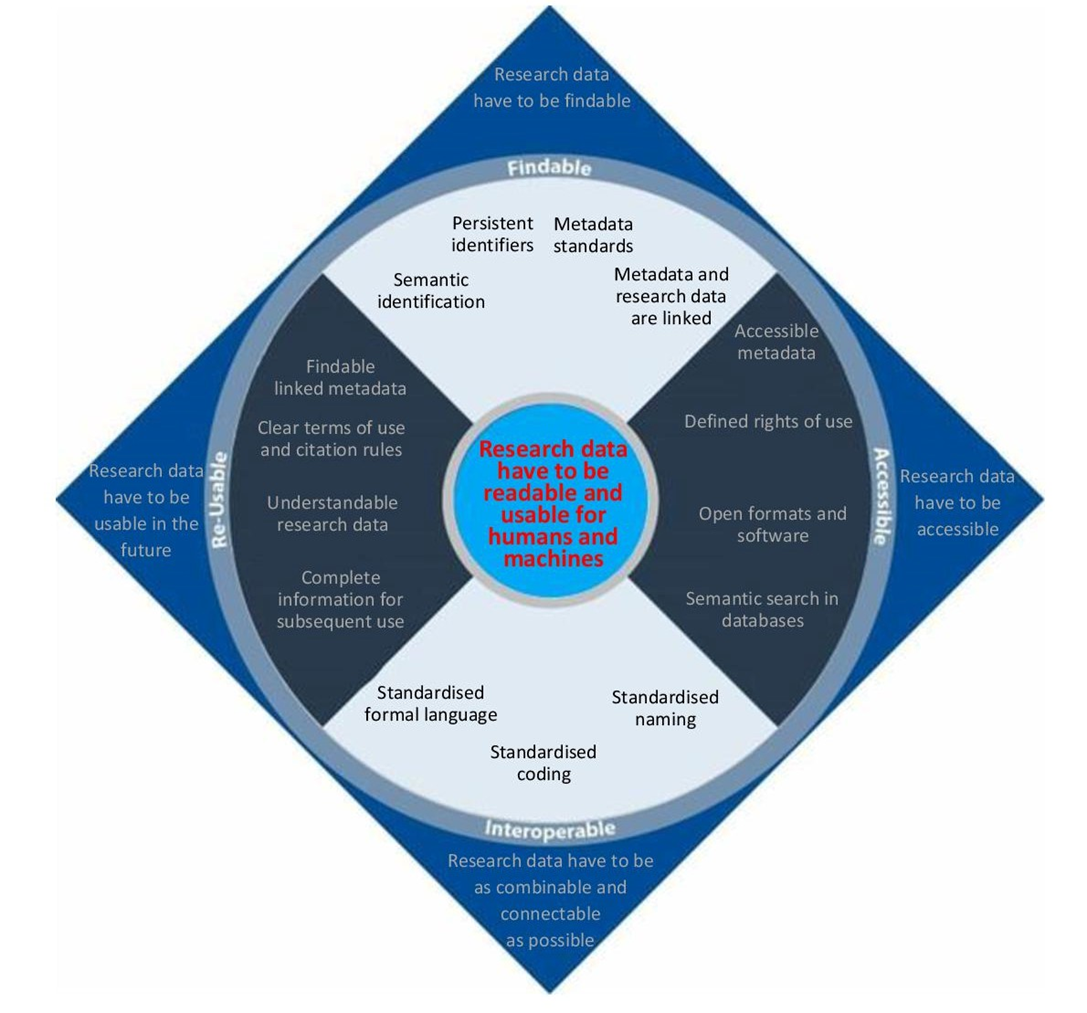
Fig. 5.1: The contents of the FAIR principles. CC-BY 4.0 Henrike Becker, graphically adapted by Andre Pietsch
-
-
-
processing time: 13 minutes, 47 seconds
processing time (without video): 10 minutes, 35 seconds-
6.2 Data and quality – Which criteria are relevant?
Data quality criteria
Perhaps you want to conduct a survey on the risk of car theft based on place of residence, i.e. postcodes. Or you want to use a questionnaire to find out whether there is a connection between academic success and school-leaving grades. In any case, you collect data that you evaluate. To do this, the following dimensions of data quality must be fulfilled, whereby not all dimensions play a role at the same time, depending on the goal and purpose of a data collection.
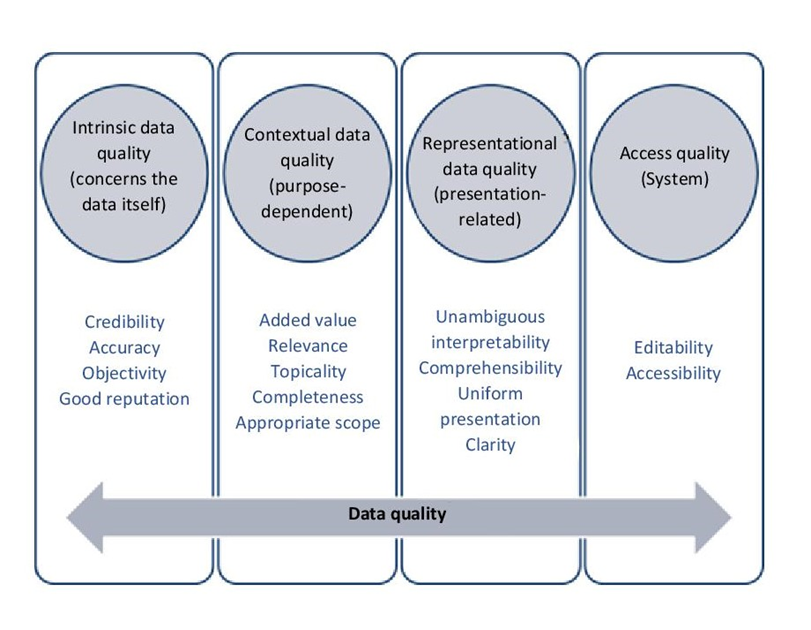
Fig. 6.1: Overview of data quality criteria, source: FOKUS
These criteria go back to Richard Wang and Diane Strong (1996). They describe high-quality data as data that is considered appropriate by the data users (including yourself) both now and in the future. In order for research data to be interesting and re-used years later, the data must be described as thoroughly as possible. Therefore, it is important to document the data well and include metadata (see Chapter 4) as well as any created and necessary research software to open and view the files.
An example – data quality criteria and their implementation
Using the example of the creation of a table with company address data, the criteria of data quality are exemplified in the following. With the help of the overview, it should be possible to gain quick insights into the distribution of customers according to federal states and to be able to send invoices specifically to the right contact persons. The table contains the following features:
- Internal customer number
- Company name
- Street
- House number
- Postcode
- Location
- State
- Last name contact person
- First name contact person
- Telephone number
The goal of every scientific enterprise is the generation of knowledge. In a process, this is gained from information, which in turn is derived from data.
In order for this to happen, it is important to clearly name the columns in this example. Only then, it becomes clear that a certain sequence of numbers and symbols (data) stand for a certain fact (information). Even if the assignment is known to the researchers at the time of data collection, this metadata is still necessary to be able to understand the data collection in the future. Likewise, of course, the data itself must also meet quality criteria.
The criteria in detail
Intrinsic data quality:
- Credibility: For this, the data must be trustworthy and reliable. For our example project, you can increase the credibility of your data by explaining where the data comes from.
- Accuracy: Correctness includes the correct recording of the data. In our example, the name “Westphalia” would be wrong, because the correct name is North Rhine-Westphalia. If the customer actually comes from Saarland, the name North Rhine-Westphalia would also be incorrect.
- Objectivity: Your data is objective if it does not contain any evaluations. In this example, an addition such as “complicated person” to the first or last name of the contact person would violate the criterion of objectivity.
- Good reputation: This is about the reputation of your data source. For example, data you get from other research projects or professional information portals may be considered more reliable than data from a data broker or data collected through a general internet search.
Contextual data quality:
- Added value: The information offers added value if it can be used to fulfil the intended tasks. In this example, this could be a query on all companies in a certain federal state.
- Relevance: Data is relevant if it provides the user with necessary information. For example, customer data from Switzerland would have added value in terms of information, but would not be relevant for the distribution of companies across the German federal states.
- Topicality: Your data is up to date if it reflects a corresponding status in a timely manner. In this example, a four-digit postcode would not be up to date because Germany switched to a five-digit system in 1993. Information about the current status can be obtained, for example, from the metadata supplied, documentation materials or date information in the document itself (date: ..____).
- Completeness: Your data is complete if no information is missing. If, for example, only 10 of the 16 federal states were included in the customer data table or if there were no address data for some of the customers, this would mean a loss of completeness.
- Adequate scope: The data is available in an adequate scope if the requirements can be met with the amount of data available. In our example, this means that for the goal of sending invoices, address data and information on who the responsible contact person is are sufficient, and telephone numbers are not necessary for this case.
Representative data quality:
-
Unambiguous interpretability: Data is unambiguously interpretable if it is understood in the same way by everyone who works with it.
-
Comprehensibility: Your data is comprehensible if it can be understood by the data users and used for their purposes. For our goal of creating a client database, this means that the listed contact persons are listed with their first and last names and not with descriptions like “the woman on the third floor with the brown hair”.
-
Uniform presentation: If the data is presented in the same way throughout, it is uniform. In our case, this means deciding for the indication of the postcode, for example, whether the sequence of digits is preceded by a “D-“.
-
Clarity: The clarity of data is ensured when it is presented in a way that is easy to grasp. In our example, this means setting up different columns for the various details so that the details can be output in a content-separated and non-condensed form. For example, we would like to have an address information according to the following pattern
Ms Iris Mueller Blaue Strasse 20 D-34567 Gruenstadtand not:MrsIrisMuellerBlaueStrasse20D-34567Gruenstadt
Access quality:
- Workability: This criterion is fulfilled if your data can be easily modified for the respective purposes of use. For our example database, this is the case if the names of the responsible contact persons can be edited. In this way, possible changes can be implemented promptly. If the table was available in PDF, for example, it would not be possible to edit it.
- Accessibility: In our example case, the persons concerned can directly access the data and generate an address, and they do not have to call somebody to ask for the address data.
-
An example – The result
And this is what the result finally looks like. By taking a closer look, however, you might realise that the data quality dimensions were not implemented without errors in the result. Can you find the mistakes?
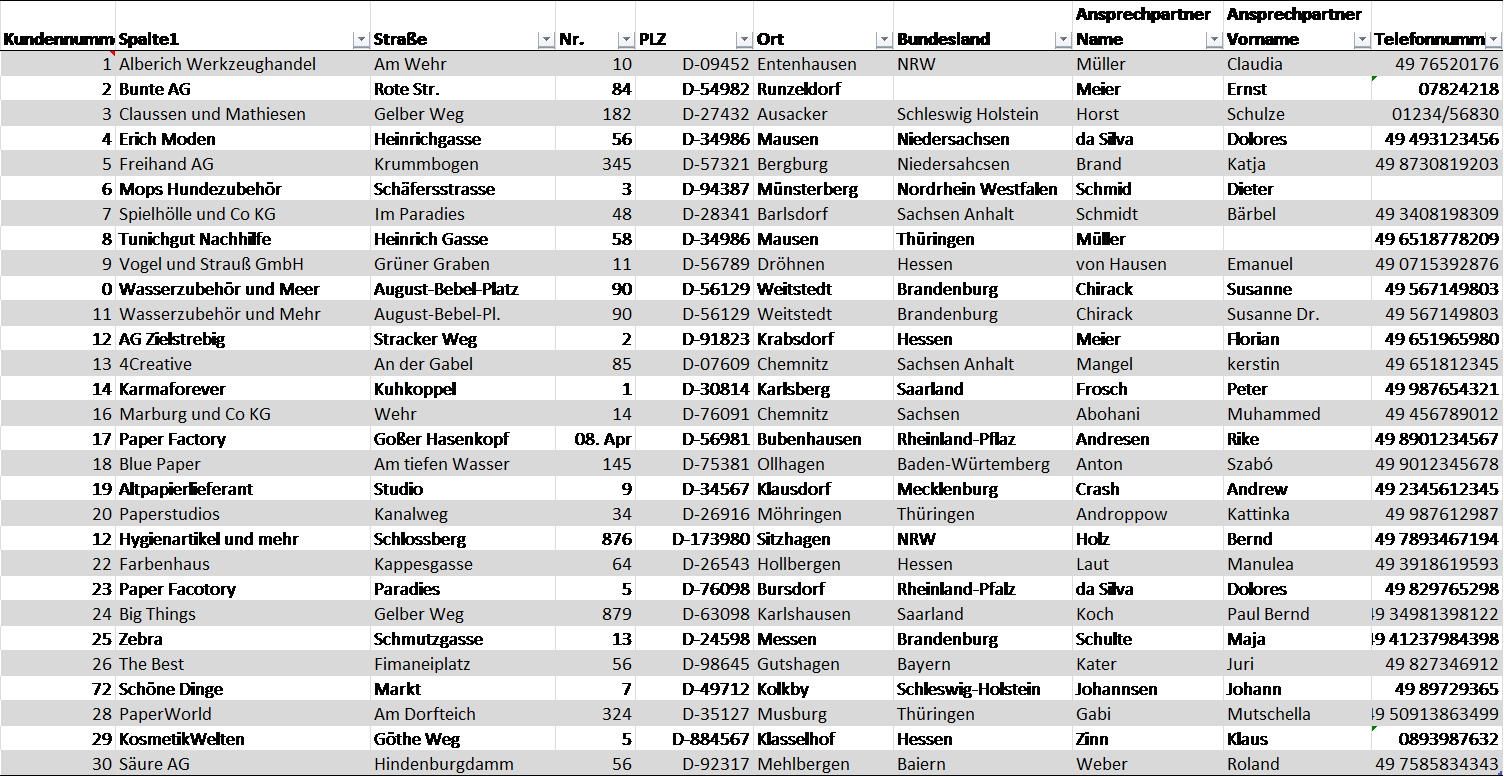
Fig. 6.2: Example table on data quality
For an exact error analysis, please watch the following video:
-
-
-
processing time: 21 minutes, 46 seconds
processing time (without video): 11 minutes, 53 seconds-
7.4 Directory structure
A directory structure (also called directory tree) is the arrangement in which folders are created. Hierarchical structures make it easier to find data (see Figure 7.1).
Fig. 7.1: Example of a directory structure or directory tree, source: Biernacka et al. 2018, p. 51
The directory structure should be clearly visible and thus understandable for other researchers. Here are some tips:
- Use clear designations for your folders.
- Avoid identical designations / names for subfolders within a branch in the directory tree.
- Ensure a balance between the width and depth of the structure. Avoid both putting many, thematically different files in one folder and creating unnecessarily many subfolders in one directory.
- Prefixing folders with underscores ("_") or numbers (01, 02, 03, etc.) can help to structure them.
To document all naming conventions and filing structures, it is also helpful to create a text file that contains all the necessary information to be able to understand the contents of the folder. This should always be saved at the top level and in .txt format to ensure readability without a special programme.
-
7.5 File Naming
Filename:
The file name should be objective and intuitively comprehensible for everybody. Naming and labelling can be done according to the following three criteria:
-
System – important for later access and retrieval of the data is consideration of the system under which the file is stored.
-
Context – the file name contains content-specific or descriptive information so that it remains clear to which context the file belongs, regardless of where it is saved, e.g. “Schedule.pdf” or “ScheduleProjectName.pdf”.
-
Consistency – choose the naming convention in advance to ensure that it can be followed systematically and contains the same information (such as date and time) in the same order (e.g. YYYY-MM-DD). File names should be as long as necessary and as short as possible to remain clear and readable under any operating system. For uniform naming, you can resort to the following naming components:
- Content
- Creator
- Creation date
- Processing date
- Name of the working group
- Publication date
- Project number
- Version number
Spelling:
There are different notations for naming files. The following points are important when naming files:
- Special characters (like { } [ ] < > ( ) * % # ' ; " , : ? ! & @ $ ~), spaces and dots should be avoided, as they are interpreted differently under different systems, which can lead to errors. Also avoid umlauts (ä ö ü). With most operating systems, you can replace spaces with underscores or capitalise the first letter of words. Writing with capital letters is also called CamelCase, in reference to the humps of a camel (see Figure 7.2). The spelling with underscores is called snake_case (see Figure 7.3).
- To enable chronological sorting, it is advisable to start the name with a date, for example YYMMDD_Name or YYYYMMD_Name:
- 20181130_snake_case.txt
- 20181123CamelCase.txt
- Other examples of uniform naming:
- 20160512_climate_measurement1_original.jpg
- 20160522_climate_measurement1_MHU_extract.jpg
- 20160523_climate_measurement1_MHU_extract_edited_colour.jpg
- Automatically generated names (e.g. from the digital camera) should be avoided as they can lead to conflicts due to repetition. When deciding on the naming convention, do not disregard scalability: e.g. choosing a two-digit file number limits the data to 00-99 files.
- Not only for larger projects, but also for smaller research projects, it is worthwhile to record the chosen naming conventions in writing. In particular, explain chosen abbreviations in a data management plan or a readme file. It is often difficult to reconstruct these conventions years later.
- If you have an ID (see also Chapter 4) or study number, you should include it in order to be able to assign the data to a study and a researcher without any doubt (especially if several researchers are working on one project).
- Use abbreviations to indicate the type of data; e.g. questionnaire, experiment, excerpt, audio file, etc.


Fig. 7.2: Visualization camelCase
(Source: Lea Dietz)Fig. 7.3: Visualization snake_case
(Source: Lea Dietz)
Renaming:
Windows offers several alternatives for renaming existing file names. A simple renaming is possible by right-clicking and selecting the context point. Furthermore, after marking the respective file, the “F2” key on the keyboard can be used.
If you want to rename several files at the same time according to certain conventions, you need suitable software. This exists for most operating systems.
Windows
Mac
Linux
- GNOME Commander
- GPRename
- Unix: For Unix, the command “rename” can be helpful to find and rename files with regular expressions.
The following video by Christian Krippes (2018) briefly summarises the most important basic rules for structured and clear file naming: https://www.youtube.com/watch?v=M76gSb9Urmg

-
-
7.7 Databases and database systems
Suitable conventions for naming and storing files are already an important building block for efficient data organisation. However, if you work with a particularly large number of files or have special requirements for the structuring of your data, especially with regard to searchability, the use of database systems can be helpful. Here, not only are the files themselves sensibly structured, but they are also recorded in a database and provided with metadata (see Chapter 4). The metadata enable targeted filter and search functions. For example, an image database could quickly and conveniently display all images taken by a certain agency at a certain place at a certain time. Figure 7.4 illustrates the basic concepts of data organisation and their hierarchical relationship.
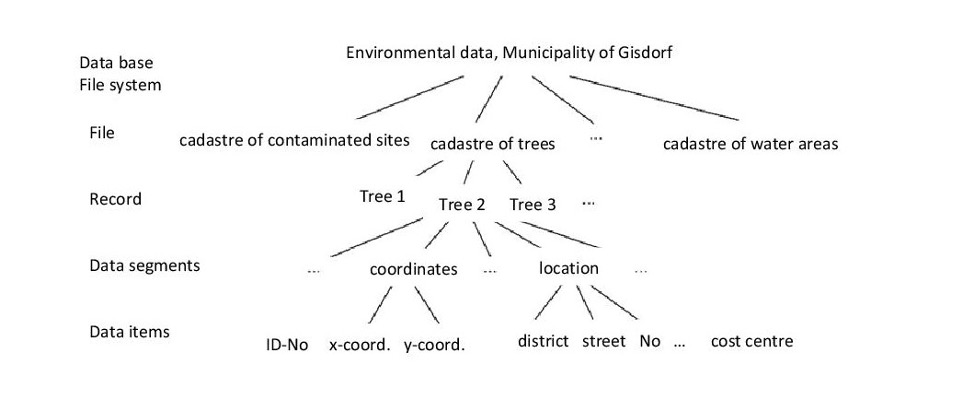
Fig. 7.4: Basic concepts of data organisation (De Lange 2006: 328).
At the lowest level of data organisation are data fields. These contain attribute values according to which they can be logically assigned to data segments (data groups). Several data segments build up a data record. Logically related data sets then form a file, while related files form file systems or databases.
However, databases are not sufficient for organising data for many user requirements; for example, some data must be stored several times in different locations in order to be able to use it for different applications. In addition, data protection can only be guaranteed with difficulty by assigning access rights. Therefore, database systems are needed. “A database system (DBS) consists of the database administration system or database management system (DBMS) and several databases (DB, also databases)” (De Lange 2006: 332). But what are databases and database management systems? A database consists of “multiple, interlinked data” (Herrmann 2018: 5), making it a collection of data whose data “are logically related” (Herrmann 2018: 5). The database is managed by the database management system; the latter is therefore software. Thus, database systems offer users efficient and bundled access to data and should fulfil the following requirements (De Lange 2006: 333):
- Evaluability of the data according to any characteristics
- Simple query options and evaluation, fast provision of data
- Allocation of different usage rights to the individual users
- Data and user programs are independent of each other, so the user only needs to know the logical data structures, while the DBS takes care of the organisational management
- No data duplication and data integrity
- Data security in the event of hardware failures and user programme errors
- Data protection against unauthorised access
- Flexibility with regard to new requirements
- Allowing multi-user access
- Compliance with uniform standards
The most common database management systems include Oracle, MySQL, Microsoft Access and SAP HANA.
-
-
-
processing time: 18 minutes, 3 seconds
-
8.2 Storage media and locations: advantages and disadvantages
As already noted in Chapter 7, research data should be saved regularly, and progress and changes should be marked and well documented via versions if possible.
Saving should be done on different media. When deciding on a medium, you should consider the following factors according to Ludwig/Enke (2013, p. 33):
- Size of the dataset
- Number of datasets
- Frequency of data access
Storage media have different properties, which means that there are sometimes considerable differences in protection against data loss and unauthorised access depending on the medium. The following is a compact overview of the properties, advantages and risks of the most common storage media and locations:
Own PC
Advantages
Disadvantages
- Ownership for security and backup
- own control
- everything that happens to the PC happens to the backup
- Possibly lack of resources and know-how to configure and check the quality of the backup copies.
- Individual solutions are time-consuming, costly, and inefficient in relation to a working group.
Mobile storage medium (e.g. CD, DVD, USB stick, external hard drive)
Advantages
Disadvantages
- Easy to transport
- can be stored in a lockable cabinet or safe
- Particularly easy to lose and can be easily stolen, therefore extremely insecure
- Content is not protected in case of loss if it has not been encrypted beforehand
- Sensitive to temperature, air quality and humidity
- External hard drives are particularly shock and wear-prone
Institutional storage locations (e.g. server of your university)Advantages
Disadvantages
- Backup of the data is ensured
- Professional implementation and maintenance
- Storage in accordance with the institution's data protection policy
- Data protection regulated via access rights
- Can be used worldwide for mobile working
- Speed depends on the network
- Access to backups possibly delayed by official channels
- It may be unclear which security criteria are applied and which security strategies are used
- possibly associated with higher costs
External storage locations (e.g. cloud services of external companies)
Advantages
Disadvantages
- easy to use and manage
- are professionally maintained
- Can be used worldwide for mobile working
- Depending on the provider, the connection may be insecure
- depending on access to the internet
- Upload and download can take a long time
- Access to backups possibly delayed
- Unclear which security criteria are applied and security strategies are used and whether these comply with the specifications for sensitive data
- many institutions have issued special regulations for the use of such services
Tab. 8.1: Advantages and disadvantages of different storage media and locations
CDs and DVDs belong to the so-called optical media. They should always be stored in suitable containers at about 30-50 % humidity and at a stable temperature between -9°C-23°C. However, magnetic storage media, e.g. hard disks or tapes, are also very wear prone (Corti et al., 2014, p. 87).
The use of free cloud storage services, such as Dropbox, OneDrive or Google Drive, should be avoided. As the server location for these providers is based in the US, the law there applies to the data and your privacy, which must be viewed critically, especially in view of the USA PATRIOT Act of 2001, as the data is not protected from all unwanted access by third parties and it is not possible to control what happens to the data.
Frankfurt UAS offers the use of Nextcloud as a safe alternative to all university members (with the exception of students) with a valid CIT-Account.

Nextcloud is an open source solution for storing files (file hosting). Functionally, it is comparable to Dropbox, Google Drive or other sync-and-share services. However, all files remain stored on the university's servers. There are five gigabytes available per user for file storage. The files can be synchronized with local storage via a client or accessed at nextcloud.frankfurt-university.de. For more information, visit the Nextcloud Knowledge Base on Confluence.
Non-digital media should not be forgotten either. Much data is handwritten or printed on paper-based materials (e.g. photos). Here, sunlight, acid or fingerprints in particular contribute to quick wear. If data is stored on paper, according to Corti et al. (2014, p. 87) you should...
- ...use acid-free paper.
- ...use folders and boxes.
- ...use stainless steel paper clips.
You should also scan the data so that it is available in a digital format. If necessary, this digital data can then be converted back into a material format by printing, for example. The PDF/A format is particularly suitable for transferring data into a digital format. However, not all documents can be converted to PDF/A without problems. However, there are free tools that can check PDF/A conformity. If the format is not suitable for your data, simply scan it as a PDF.
It should also be noted that at least two people should have access to the data in order to guarantee the availability of the data even in case of illness or absence.
-
8.5 Backup
In contrast to these measures, with which you delete data permanently and safely, data can also be lost unintentionally. To avoid deleting data by mistake or destroying it by accident, you should backup your data regularly.
The creation of a backup copy of data should always be done on a storage medium that is separate from the usually used infrastructure – in a planned and structured way. Thus, data should be backed up as regularly as possible in order to be able to carry out a data reconstruction as easily as possible. However, before you backup your data, you should clarify organisational questions:
- Are there already ongoing backup plans? What do they look like?
- How often should a backup be made of what?
- Where should the backups be stored?
- How should the backups be saved? (e.g. labelling, sorting, file format)
- Which backup tools can help?
- How is sensitive data handled?
It is recommended to use an automated routine. Partial data that is currently being worked on should be backed up daily if possible. Furthermore, it is advisable not to overwrite them every day, as this allows one to reconstruct errors if necessary or also to undo changes that were done erroneously. In addition, a weekly complete backup should be done. The principles of the 3-2-1 backup are useful here (see figure 8.1).
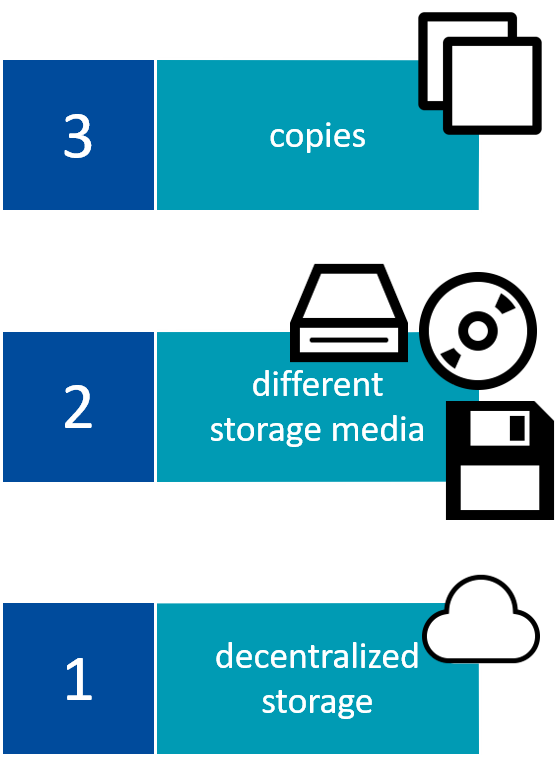
Fig. 8.1: The 3-2-1 backup rule (CC-BY SA, Andre Pietsch)
A decentralized storage location refers to the institutional as well as external storage locations listed in Table 8.1. You should always prefer an institutional, decentralised storage location.
The backup or the resulting data recovery should be checked at the beginning as well as at regular intervals. Most institutions offer an automatic solution in which all data is stored exclusively on backed-up drives provided by the university computer centres. This professionalisation ensures that the backups won’t be forgotten, and that the configuration of the backup system does not need to be done individually.
In addition, you can check your backups after they have been created using checksums. To do this, however, you must have MD5 or SHA1 checksums created for these files after the backup files have been created. The utility “File Checksum Integrity Verifier”, FCIV for short, provided by Microsoft, helps you to do this. Instructions on how to use it can be found here. If the checksums of both your original data and the backup are identical, so is the data. In this way, you can check the integrity of your data and determine whether any errors may have occurred when copying the data. Incidentally, if you also publish software code, it is customary in the programming field to include the checksum of the installation file (“*.exe”) with the download so that interested users can check beforehand whether it is an original installation file and not possibly a file infected with viruses.
-
-
-
Disclaimer: No legally binding information! For specific legal advice on your research, please contact the legal department or the data protection officer of the university (dsb@fra-uas.de).
processing time: 67 minutes, 10 seconds
processing time (without video): 20 minutes, 36 seconds-
9.1 Introduction & learning objectives
Legal issues in dealing with research data arise at every stage of the research data life cycle. Figure 9.1 provides an initial overview of legal aspects that need to be considered in each phase of data handling.
Edit based on: Paul Baumann/Philipp Krahn, Rechtliche Rahmenbedingungen des FDM - Grundlagen und Praxisbeispiele, Dresden 2020, Slide 4
Fig. 9.1: Legal aspects of research data management in research data lifecycle
You do not have to find solutions for all the legal details of handling your research data yourself. However, if you want to work in the spirit of good scientific practice and research ethics, you should know at least the basics of some legal scenarios.
After completing this chapter, you will be able to...
• ...name the most important legal areas in dealing with research data • ...take concrete steps to implement your research project in compliance with the law • ...decide whether and how you can publish your data • ...contact the right place if you have any questions
If you have complex legal questions, you can contact the legal department and/or the data protection officer of the university. In addition, your research data management officer will also be happy to help you.
-
9.3 Data protection
Data protection rights must be observed when collecting, storing, processing, and passing on research data relating to individuals. If you work as a researcher at a Hessian university with such data, it is advisable to know the main features of the following legal texts in particular:
- General Data Protection Regulation of the European Union (GDPR)
- German Federal Data Protection Act (BDSG)
- Hessian Data Protection and Freedom of Information Act (HDSIG)
The following video briefly introduces the data protection laws that are particularly relevant to scientific research and explains how they relate to each other:
Source: Excerpt from MLS LEGAL - Data Protection in Research (YouTube) [Creative Commons licence with attribution (reuse permitted)]
Data without personal reference or anonymised information, on the other hand, do not fall under data protection law and can usually be processed freely, taking into account other rights (e.g. copyrights).
What exactly distinguishes personal data from other (anonymous) research data is explained in detail in the following section. In case of doubt, you should assume a personal reference to avoid liability risks.
9.3.1 Personal data and special categories of personal data
According to Art. 4 (1) of the GDPR, personal data is any information relating to an identified or identifiable living person. Examples of personal research data include survey data in the social sciences or health data in medical research.
An identifiable person is one who can be identified directly or indirectly by means of attribution:
- in particular to an identifier such as a name, an identification number, location data, an online identifier or
- to one or more particular characteristics that are an expression of the physical, physiological, genetic, mental, economic, cultural, or social identity of that natural person.
The following cases in particular have recently been decided in case law:
- Images, film, and sound recordings if there is a reference to a person
- IP addresses
- written answers of a candidate in a vocational examination
- Examiner's comments on the assessment of these answers
In determining whether a person is identifiable, the GDPR requires that account be taken of all the means likely to be used by the data protection officer or by any other person, in normal circumstances (in terms of cost and time), to identify the person (Recital 26 GDPR).
Source: Excerpt from MLS LEGAL - Data protection in research (YouTube) [Creative Commons licence with attribution (re-use permitted)].
In addition, there are categories of data in case law that are considered particularly sensitive. These include, for example, data on a person's state of health, sexual orientation, and political or religious views. A list of these special categories of personal data can be found in Article 9 of the GDPR.
This data is subject to special protection and special due diligence obligations during processing. This means, for example, that participants in scientific studies must explicitly consent to the processing of these special categories of personal data before the data is collected. Further aspects are explained in the following video:
Source: Excerpt from MLS LEGAL - Data protection in research (YouTube) [Creative Commons licence with attribution (re-use permitted)].
When processing personal data, the so-called Principles relating to processing of personal data (Art. 5 GDPR) must be observed:
- Personal research data may only be collected if they are necessary to achieve the research purpose.
- The collection and processing must be done transparently and with due probity vis-à-vis the data subjects.
- Data subjects must at all times be able to understand the processing of their personal data and must not be misled by false and omitted information.
- Protecting privacy by safeguarding personal data should be central to all collection and processing considerations.
- The data must also correctly reflect the circumstances of the person concerned, i.e. it must not falsify them.
- They shall be protected against misuse (e.g. removal, alteration, damage) technically and organisationally within the bounds of what is reasonable.
9.3.2 Informed consent and legal permission standards
Personal research data may only be collected and processed with the informed consent of the person concerned or with a legal standard of permission (so-called principle of prohibition with reservation of permission).
According to Recital 32 p.2 GDPR, the following requirements can be stated for informed consent:
- Consent must be freely given (i.e. without physical or psychological influence)
- Especially when processing sensitive personal data (according to Art. 9 or 10 GDPR), it is advisable to write down the consent.
- The persons giving consent must be able to understand in advance which of their personal data will be used how, for what, by whom and for how long. In other words, people should be put in a position in which they are able to assess the consequences of their own consent.
On the other hand, legal permissions are granted without the consent of the data subject. Particular importance is attached to the exceptions for scientific research purposes contained in § 27 BDSG, but also in many state data protection laws (e.g. § 13 LDSG-BW, § 17 DSG-NRW, § 13 NDSG).
According to this, the processing of personal data is permitted if the interests pursued with the research project outweigh those of the persons concerned (cf. forschungsdaten.info). However, since this rarely applies, you should always obtain consent in case of doubt.
Consent does not require any special form. However, it must be verifiable – e.g. in the event of a review by the data protection supervisory authority – so that written or electronic documentation is strongly recommended. The declaration of consent should contain at least the following information:
- Person responsible for data collection (legal entity) who is also the addressee of the declaration of consent;
- Project title;
- Specific information on the type of data collected;
- Data processing procedures, data protection officer;
- Reference to voluntariness, to the right of withdrawal, reference to the consequences or the absence of consequences in the event of refusal or withdrawal;***
- particularly important: Intended use(s).
Above all, the data subject must be informed that their consent is completely voluntary, that they can therefore also refuse to consent and – if they do – that they can revoke the consent with effect for the future at any time, but that previous usages cannot be reversed (Cf. https://www.forschungsdaten-bildung.de/einwilligung).
The declaration of consent must be supplemented with information on the processing of the data. This includes the legal basis and purposes of the processing (insofar as these go beyond the processing), any data transfer to countries outside the EU, the storage or deletion periods of the personal data and the right of appeal to a data protection supervisory authority (cf. Watteler/Ebel 2019: 60).
Consent can also be given in the abstract for scientific purposes that are not known at the time of collection (so-called broad consent). However, the more specific the description, the more likely the scope of the consent in question will be able to extend to uses that go beyond the use of the primary purpose.
If the publication of data within the framework of the RDM is intended, the consent should explicitly include the storage and publication of the data. A practicable compromise between abstract and concrete broad consent can, for example, be a graded consent.

Fig. 9.2: Example of informed consent in "broad consent format" (source: Baumann/Krahn 2020).
Das folgende Video fasst alle Aspekte zur informierten Einwilligung und zu den gesetzlichen Erlaubnistatbeständen noch einmal zusammen:
Source: Excerpt from MLS LEGAL - Data protection in research (YouTube) [Creative Commons licence with attribution (re-use permitted)]Further information
Some disciplines offer assistance and examples of wording for written informed consent (cf. e.g. VerbundFDB, RatSWD).
- Model declaration for oral or written interviews of the Arbeitskreis Deutscher Markt- und Sozialinstitute (Working Group of German Market and Social Institutes)
- Recommendations and model consent forms of the RatSWD
- Formulation examples for “informed consents” of the VerbundFDB
- Template for the Informed Consent for the Processing of Personal Data (German / English) by Qualiservice
- Handout on Informed Consent (explanations on the use of the QA templates)
9.3.3 Means of removing identifying features
In general, personal research data must be anonymised after collection as soon as possible for the research purpose (at the latest when the research project is completed).
Anonymisation**
A change in the data to such an extent that the individual data on personal or factual circumstances can no longer be attributed to a specific or identifiable natural person (so-called absolute anonymisation) or can only be attributed to a specific or identifiable natural person with a disproportionate effort in terms of time, costs, and manpower (so-called de facto anonymisation).
The first step is to remove direct identification features (name, address, telephone number, etc.). Often, however, this is not sufficient to eliminate a reference to a person. In this case, reducing the accuracy of the information (aggregation) can be an effective measure that also allows certain parts of the information to be retained.
Aggregation
Summary of several individual values of the same kind to reduce the granularity of information. From the summarised information, it is no longer possible to draw conclusions about the individual pieces of information.
Here, detailed individual information (e.g. salary in the last month) is grouped into classes (e.g. lower, middle, upper class). The degree of aggregation necessary to exclude a personal reference can vary. It essentially depends on which other potential identification features are available in the data or can be obtained from external sources.
Example of gradual aggregation
Address → City → State → East/West → Country → Continent
In each case, careful consideration must be given to which of the available means appear to be the most suitable and proportionate to remove the identifying characteristics in such a way that no or only very limited de-anonymisation is possible, even with any additional knowledge as well as extensive capacities for data research and aggregation.
Postponement of anonymisation is only possible if characteristics that reveal a personal reference are needed to achieve the research purpose or individual research steps. This is the case, for example, during an ongoing research project that uses biometric data.
In this case, however, the personal characteristics must be securely and separately stored immediately after collection. This can be done, for example, by pseudonymising the personal research data.
Pseudonymisation
The separation of personal characteristics immediately after collection from the rest of the data, so that the data can no longer be assigned to a specific person without adding information.
One example is the use of a key table that assigns corresponding ID codes to the plain names of persons. In this way, the personal reference can only be established if one is in possession of the key table. If necessary, this can also be held by an independent trustee.
However, the data processed in this way continue to have a personal reference until the personal characteristics to be stored separately are deleted and are therefore subject to the requirements of data protection law.
Source: Excerpt from MLS LEGAL - Data protection in research (YouTube) [Creative Commons licence with attribution (re-use permitted)]. -
9.4 Decision-making authority
In addition to data protection, another important question is who can decide on the handling of the research data, especially its publication. As a rule, the person to whom the research data are “assigned” can also decide on their handling, such as their publication. Such an “assignment” can result from copyright law, service contract law or patent law, for example.
9.4.1 Copyright and Ancillary Copyright Law
As a rule, the protectability of individual research data under copyright law can only be assessed on a case-by-case basis and even then, not with sufficient legal certainty. Nevertheless, different case groups of research data can be distinguished according to the concrete type of content and, above all, how it was obtained:
- Qualitative research data are, for example, linguistic works such as qualitative interviews or longer texts. They can contain copyrighted formulations, structures and thought processes. Copyright protection never applies if the wording, structure, and line of thought are essentially predetermined by professional practice.
- Scientific representations, such as drawings, plans, maps, sketches, and tables, may be subject to copyright protection if the representation is not dictated by factual constraints or scientific conventions, but instead gives the scientist room for manoeuvre.
- Under the same conditions, photographs and other photographic images are also protected by copyright. In addition to photographs, images from imaging procedures, such as X-ray, magnetic resonance and computer tomography images are included, as well as photographs and individual images from films.
- Quantitative data are, for example, measurement results or statistical data. In the context of standardised surveys, there will be no copyright protection in most cases.
- (Quantitative) research data, the arrangement and compilation of which has the effect of establishing individuality, is a so-called database work (Section 4 UrhG(German Copyright Law)). Only its structure and not the information as such is subject to copyright protection.
- Metadata often are relatively short, purely descriptive representations. They are usually not protected by copyright. In principle, they can only be protected in the rare cases where they contain, for example, longer sections of text or photographs.
Photographs and other photographic images may also be protected by a neighbouring right under Section 72 UrhG. The following figure by Brettschneider (2020) attempts a generalisation of the protectability of research data as copyright works:
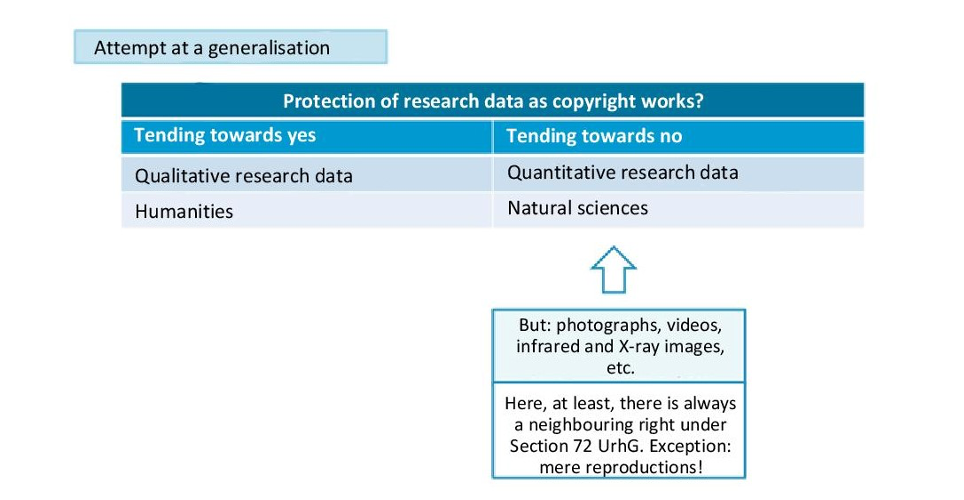 Fig. 9.3: Work quality of research data, source: hhttps://zenodo.org/record/3763031, slide 5.
Fig. 9.3: Work quality of research data, source: hhttps://zenodo.org/record/3763031, slide 5.Compilations of research data within the framework of a database can be protected by copyright as a database work – but also by the database producer right (§87a UrhG). This ancillary copyright requires a substantial investment in terms of collecting, organising, and making research data accessible.
The owner of the database producer rights is usually the person who makes the essential investments, e.g. pays the researchers' remuneration and bears the economic risk. Generally, this is also the employing university or research institution. In some cases, a third-party commissioning or funding institution may also be the owner.
In the case of non-protected research data (e.g. measurement results), it is largely unclear from a legal point of view who has the decision-making authority over the data in a specific individual case. Whether a possible personal right of the scientist also allows an assignment of the research data to a person in these cases is disputed.
9.4.2 Granting of rights of use within the framework of service and employment contracts
If the creation of copyright-protected works is one of the duties or central tasks of the employment contract, the employer is granted rights of use to these so-called “compulsory works” on the basis of the employment contract or employment relationship (Section 43 UrhG (German Copyright Act)). The following “mapping” of research data result from the balance of interests with the freedom of research (Art. 5 para. 3 GG (German Basic Law)):
- As a rule, university teachers are entitled to all rights of exploitation, use and publication of the works they have created, unless there are express contractual agreements (e.g. third-party funding, non-disclosure agreements). § 43 UrhG (so-called “compulsory works”) does not apply here.
- Scientific assistants and employees are privileged under Article 5 (3) of the GG (German Basic Law) if and to the extent that the scientific work is carried out free of instructions. If the research is carried out in accordance with instructions, a tacit granting of the right to use the research data generated is to be assumed.
- In the case of students and external doctoral candidates, no rights of use are granted to the university, as they are not employees. However, different contractual agreements can be made, e.g. in the case of third-party funded projects, through which the university is granted rights of use.
The following figure illustrates the issues of the transfer of exploitation rights to the employer (“compulsory work” under Section 43 UrhG) and the balancing of interests with the freedom of research (Article 5(3) GG) according to roles as they are to be weighed in the scientific field in individual cases:
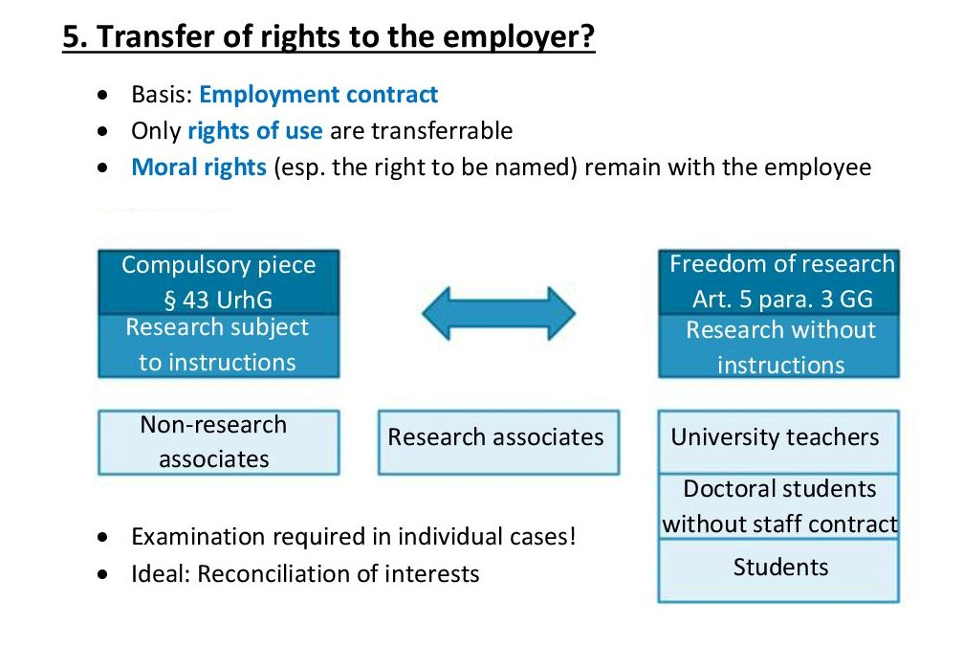
Fig. 9.4: Ownership of research data, source: https://zenodo.org/record/3763031, slide 7
It should be noted that the granting of rights of use within the framework of service and employment contracts may also be tacit if the granting of rights of use is not expressly regulated in the contract. Within the framework of the (tacit) granting, the scientist also leaves the right to determine to the employer whether and how the work is published. On the other hand, each scientist retains their right to be named.
9.4.3 Summary
The following video explains in summary the complex interplay of all the legal positions for the “mapping” of research data that have been elaborated so far and in a few additional aspects, it even goes beyond (e.g. software, data carriers):
Source: Excerpt from "Open Science: From Data to Publications" - Brettschneider, Peter (2020): Legal Issues in Publishing (https://www.youtube.com/watch?v=CrvnMLxGppI) [Creative Commons licence with attribution (reuse permitted) CC BY 4.0]
-
9.5 Publication and licensing of research data
Before data can be made publicly available, there are a number of legal aspects to consider – because not all data can or should be made public. The most important legal aspects are considered in the following decision aid in the form of a flow chart. Answering the questions will guide you through the decision-making process to a recommendation:
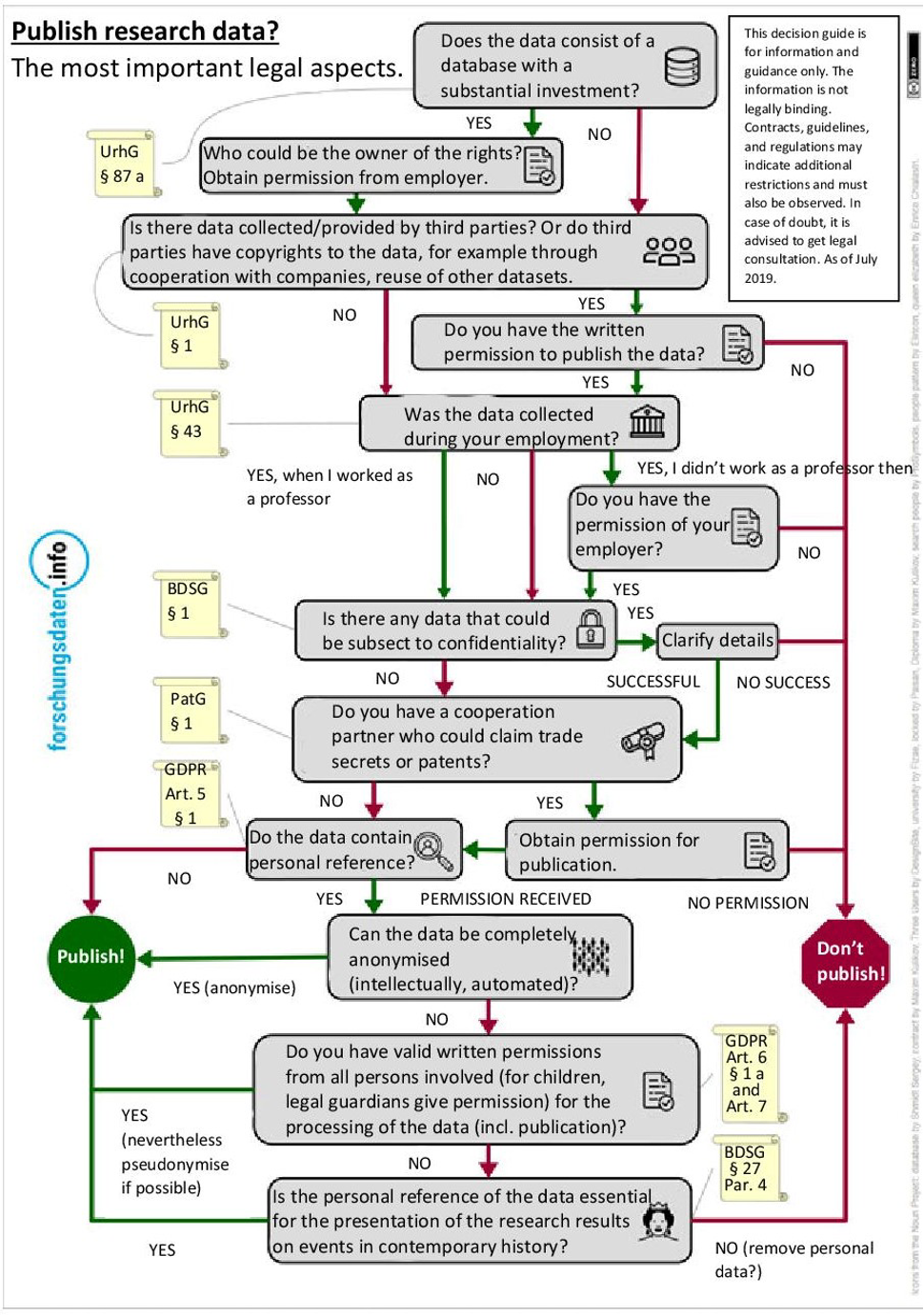
Fig. 9.5: Decision-making process for data publication, (source: forschungsdaten.info, https://zenodo.org/record/3368293)
Essentially, but not exclusively, questions of data protection and copyright must be clarified before publication. The decisive course for the possibility of publishing research data in a repository is therefore often already set when the data are collected, and the corresponding declarations of consent are obtained.
9.5.1 What are suitable licensing models?
In order for others to be allowed to use your copyrighted data, the conditions of use must be regulated. This is done by issuing a licence. If no licence exists, copyrighted data may only be used with the express consent of the copyright holder.
On the other hand, non-copyrighted research data whose use is already permitted without contractual permission (e.g. licence) should neither be restricted nor subject to conditions. For this reason, under the CC-BY 4.0 licence, for example, there is also no enforceable obligation for attribution (see clause 8a of the licence agreement).
Creative Commons licences are often used to make research data available. Just as the European Commission in its project Horizon 2020, the DFGrecommends the use of these licence types. When deciding on a specific licence, the guiding principle is “as open as possible, as restrictive as necessary”:
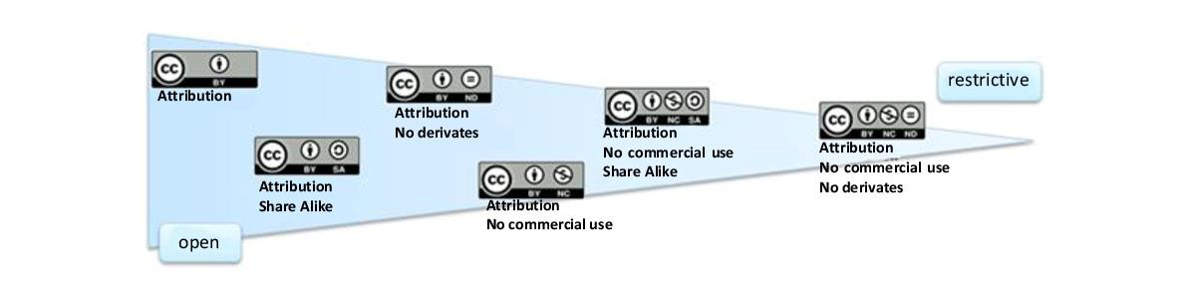
Fig. 9.6: Possible uses of data under different Creative Commons licences, source: Apel et al.
The “Abridged version of the expert opinion on the legal framework conditions of research data management” of the BMBF-funded DataJus project at TU Dresden, which investigated the legal framework conditions of research data management, advocates the following two licences:
Licence
Description
CC0(Plus)
The CC0 licence enables maximum release of the data and facilitates subsequent use. There is no right to credit. This licence is particularly recommended for metadata.
CC-BY 4.0
The CC-BY 4.0 licence makes sense if credit is desired. At the same time, the requirement to cite the source is met (safeguarding good scientific practice). The CC-BY 4.0 licence is therefore recommended for the publication of research data.
The use of further licence modules is not recommended. For example, the Creative Commons (CC) licences with the attribute “ND” (e.g. CC-BY-ND) rule out the distribution of “modified” material. This would make it impossible to make a new database publicly available that was created from parts of other databases.
Software, unlike much other research data, requires a separate licence. The use of Creative Commons licences is not recommended for this. However, different licences are also available: MIT licence, GNU General Public License (GPL), GNU Lesser General Public License (LGPL), Apache licence. The most important distinction here is between copyright licences (such as Apache) and so-called copyleft licences (such as GNU-GPL). A copyleft corresponds largely to the "Share Alike" of Creative Commons licences.
9.5.2 What can inhibit publication?
Not all research data may or should actually be published. Before you decide not to publish your data at all, you should always check whether you can take measures to enable legally and ethically unobjectionable publication. The following figure provides an overview of possible legal hurdles and corresponding solutions:
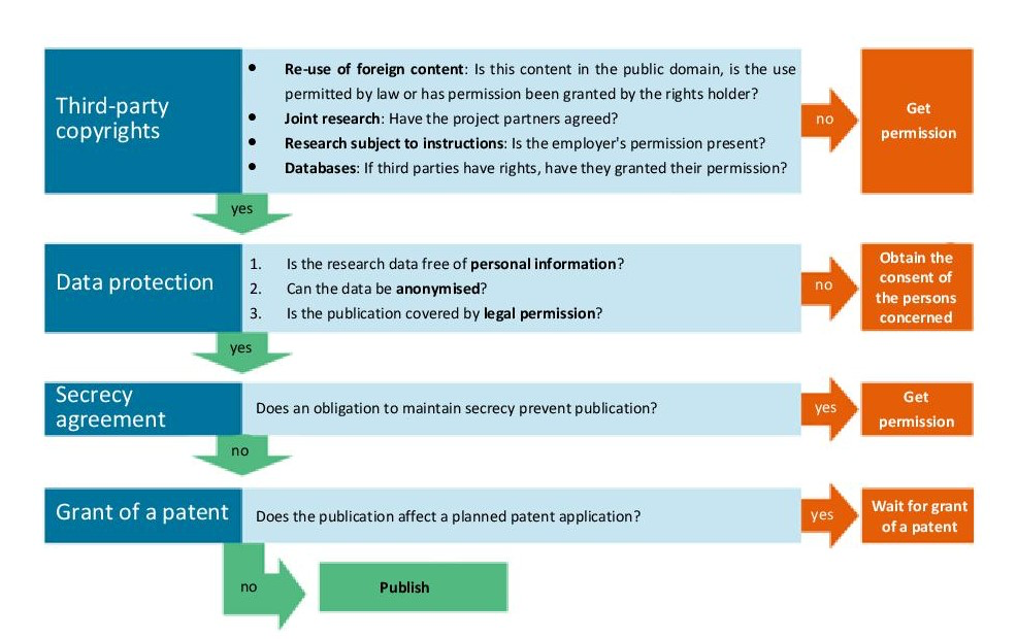
Fig. 9.7: Decision tree for data publication, source: Böker/Brettschneider (2020)
In addition, you should also take research ethics aspects into account when deciding whether to publish your research data. The following points should give you some criteria without claiming to be complete:
- Can the data be used in a way that is harmful to society?
- For example, does publication pose risks to the researched individuals (even if they have consented to the use of their data)?
- Do participating working group members have legitimate interests in preventing or delaying data publication (e.g. for the completion of qualification work)?
9.5.3 Protection of confidential information in research data centres
By using data centres or even archives, it is possible to restrict access to confidential and sensitive data and at the same time enable data sharing for research and educational purposes. The data held in data centres and archives are generally not publicly accessible. Their use after user registration is restricted to specific purposes. Users sign an end-user licence in which they agree to certain conditions, such as not using data for commercial purposes or not identifying potentially identifiable individuals. The type of data access permitted is determined in advance with the originator. Furthermore, data centres can impose additional access regulations for confidential data.1
-
9.6 Summary
The following video “From Data to Publications” concludes this chapter by explaining the complex interplay of all the legal positions on research data that have been worked out so far, and in a few aspects also goes beyond what has been explained (e.g. software, data carriers):

Source: "Open Science: From Data to Publications" - Brettschneider, Peter (2020): Legal issues in publishing (https://www.youtube.com/watch?v=CrvnMLxGppI) [Creative Commons licence with attribution (reuse permitted) CC BY 4.0] -
Test your knowledge about the content of this chapter !
-
Here is a summary of the most important facts
-