8 Data storage and archiving
Section outline
-
processing time: 18 minutes, 3 seconds
-
8.2 Storage media and locations: advantages and disadvantages
As already noted in Chapter 7, research data should be saved regularly, and progress and changes should be marked and well documented via versions if possible.
Saving should be done on different media. When deciding on a medium, you should consider the following factors according to Ludwig/Enke (2013, p. 33):
- Size of the dataset
- Number of datasets
- Frequency of data access
Storage media have different properties, which means that there are sometimes considerable differences in protection against data loss and unauthorised access depending on the medium. The following is a compact overview of the properties, advantages and risks of the most common storage media and locations:
Own PC
Advantages
Disadvantages
- Ownership for security and backup
- own control
- everything that happens to the PC happens to the backup
- Possibly lack of resources and know-how to configure and check the quality of the backup copies.
- Individual solutions are time-consuming, costly, and inefficient in relation to a working group.
Mobile storage medium (e.g. CD, DVD, USB stick, external hard drive)
Advantages
Disadvantages
- Easy to transport
- can be stored in a lockable cabinet or safe
- Particularly easy to lose and can be easily stolen, therefore extremely insecure
- Content is not protected in case of loss if it has not been encrypted beforehand
- Sensitive to temperature, air quality and humidity
- External hard drives are particularly shock and wear-prone
Institutional storage locations (e.g. server of your university)Advantages
Disadvantages
- Backup of the data is ensured
- Professional implementation and maintenance
- Storage in accordance with the institution's data protection policy
- Data protection regulated via access rights
- Can be used worldwide for mobile working
- Speed depends on the network
- Access to backups possibly delayed by official channels
- It may be unclear which security criteria are applied and which security strategies are used
- possibly associated with higher costs
External storage locations (e.g. cloud services of external companies)
Advantages
Disadvantages
- easy to use and manage
- are professionally maintained
- Can be used worldwide for mobile working
- Depending on the provider, the connection may be insecure
- depending on access to the internet
- Upload and download can take a long time
- Access to backups possibly delayed
- Unclear which security criteria are applied and security strategies are used and whether these comply with the specifications for sensitive data
- many institutions have issued special regulations for the use of such services
Tab. 8.1: Advantages and disadvantages of different storage media and locations
CDs and DVDs belong to the so-called optical media. They should always be stored in suitable containers at about 30-50 % humidity and at a stable temperature between -9°C-23°C. However, magnetic storage media, e.g. hard disks or tapes, are also very wear prone (Corti et al., 2014, p. 87).
The use of free cloud storage services, such as Dropbox, OneDrive or Google Drive, should be avoided. As the server location for these providers is based in the US, the law there applies to the data and your privacy, which must be viewed critically, especially in view of the USA PATRIOT Act of 2001, as the data is not protected from all unwanted access by third parties and it is not possible to control what happens to the data.
Frankfurt UAS offers the use of Nextcloud as a safe alternative to all university members (with the exception of students) with a valid CIT-Account.

Nextcloud is an open source solution for storing files (file hosting). Functionally, it is comparable to Dropbox, Google Drive or other sync-and-share services. However, all files remain stored on the university's servers. There are five gigabytes available per user for file storage. The files can be synchronized with local storage via a client or accessed at nextcloud.frankfurt-university.de. For more information, visit the Nextcloud Knowledge Base on Confluence.
Non-digital media should not be forgotten either. Much data is handwritten or printed on paper-based materials (e.g. photos). Here, sunlight, acid or fingerprints in particular contribute to quick wear. If data is stored on paper, according to Corti et al. (2014, p. 87) you should...
- ...use acid-free paper.
- ...use folders and boxes.
- ...use stainless steel paper clips.
You should also scan the data so that it is available in a digital format. If necessary, this digital data can then be converted back into a material format by printing, for example. The PDF/A format is particularly suitable for transferring data into a digital format. However, not all documents can be converted to PDF/A without problems. However, there are free tools that can check PDF/A conformity. If the format is not suitable for your data, simply scan it as a PDF.
It should also be noted that at least two people should have access to the data in order to guarantee the availability of the data even in case of illness or absence.
-
8.5 Backup
In contrast to these measures, with which you delete data permanently and safely, data can also be lost unintentionally. To avoid deleting data by mistake or destroying it by accident, you should backup your data regularly.
The creation of a backup copy of data should always be done on a storage medium that is separate from the usually used infrastructure – in a planned and structured way. Thus, data should be backed up as regularly as possible in order to be able to carry out a data reconstruction as easily as possible. However, before you backup your data, you should clarify organisational questions:
- Are there already ongoing backup plans? What do they look like?
- How often should a backup be made of what?
- Where should the backups be stored?
- How should the backups be saved? (e.g. labelling, sorting, file format)
- Which backup tools can help?
- How is sensitive data handled?
It is recommended to use an automated routine. Partial data that is currently being worked on should be backed up daily if possible. Furthermore, it is advisable not to overwrite them every day, as this allows one to reconstruct errors if necessary or also to undo changes that were done erroneously. In addition, a weekly complete backup should be done. The principles of the 3-2-1 backup are useful here (see figure 8.1).
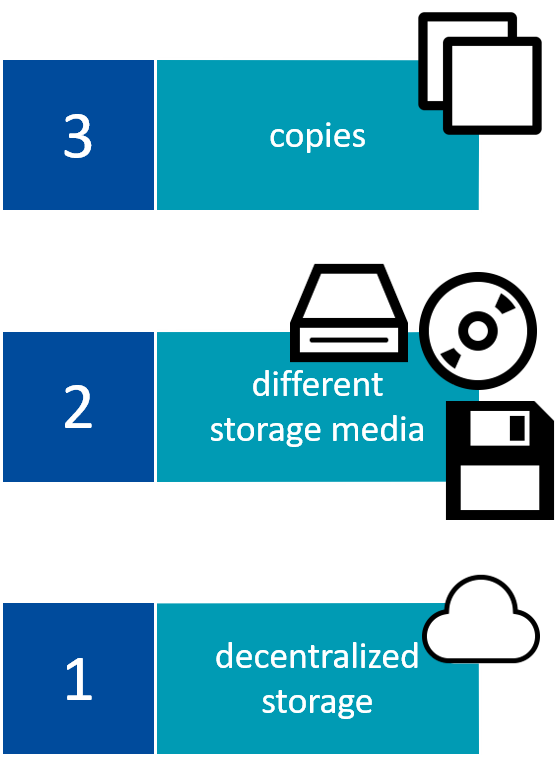
Fig. 8.1: The 3-2-1 backup rule (CC-BY SA, Andre Pietsch)
A decentralized storage location refers to the institutional as well as external storage locations listed in Table 8.1. You should always prefer an institutional, decentralised storage location.
The backup or the resulting data recovery should be checked at the beginning as well as at regular intervals. Most institutions offer an automatic solution in which all data is stored exclusively on backed-up drives provided by the university computer centres. This professionalisation ensures that the backups won’t be forgotten, and that the configuration of the backup system does not need to be done individually.
In addition, you can check your backups after they have been created using checksums. To do this, however, you must have MD5 or SHA1 checksums created for these files after the backup files have been created. The utility “File Checksum Integrity Verifier”, FCIV for short, provided by Microsoft, helps you to do this. Instructions on how to use it can be found here. If the checksums of both your original data and the backup are identical, so is the data. In this way, you can check the integrity of your data and determine whether any errors may have occurred when copying the data. Incidentally, if you also publish software code, it is customary in the programming field to include the checksum of the installation file (“*.exe”) with the download so that interested users can check beforehand whether it is an original installation file and not possibly a file infected with viruses.
-
-