7 Data organisation
Bölüm anahatları
-
processing time: 21 minutes, 46 seconds
processing time (without video): 11 minutes, 53 seconds-
7.4 Directory structure
A directory structure (also called directory tree) is the arrangement in which folders are created. Hierarchical structures make it easier to find data (see Figure 7.1).
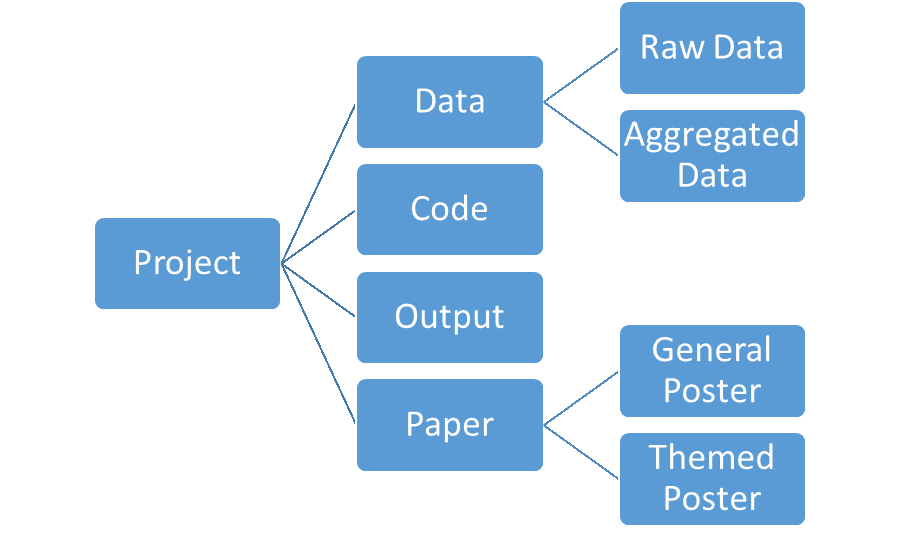
Fig. 7.1: Example of a directory structure or directory tree, source: Biernacka et al. 2018, p. 51
The directory structure should be clearly visible and thus understandable for other researchers. Here are some tips:
- Use clear designations for your folders.
- Avoid identical designations / names for subfolders within a branch in the directory tree.
- Ensure a balance between the width and depth of the structure. Avoid both putting many, thematically different files in one folder and creating unnecessarily many subfolders in one directory.
- Prefixing folders with underscores ("_") or numbers (01, 02, 03, etc.) can help to structure them.
To document all naming conventions and filing structures, it is also helpful to create a text file that contains all the necessary information to be able to understand the contents of the folder. This should always be saved at the top level and in .txt format to ensure readability without a special programme.
-
7.5 File Naming
Filename:
The file name should be objective and intuitively comprehensible for everybody. Naming and labelling can be done according to the following three criteria:
-
System – important for later access and retrieval of the data is consideration of the system under which the file is stored.
-
Context – the file name contains content-specific or descriptive information so that it remains clear to which context the file belongs, regardless of where it is saved, e.g. “Schedule.pdf” or “ScheduleProjectName.pdf”.
-
Consistency – choose the naming convention in advance to ensure that it can be followed systematically and contains the same information (such as date and time) in the same order (e.g. YYYY-MM-DD). File names should be as long as necessary and as short as possible to remain clear and readable under any operating system. For uniform naming, you can resort to the following naming components:
- Content
- Creator
- Creation date
- Processing date
- Name of the working group
- Publication date
- Project number
- Version number
Spelling:
There are different notations for naming files. The following points are important when naming files:
- Special characters (like { } [ ] < > ( ) * % # ' ; " , : ? ! & @ $ ~), spaces and dots should be avoided, as they are interpreted differently under different systems, which can lead to errors. Also avoid umlauts (ä ö ü). With most operating systems, you can replace spaces with underscores or capitalise the first letter of words. Writing with capital letters is also called CamelCase, in reference to the humps of a camel (see Figure 7.2). The spelling with underscores is called snake_case (see Figure 7.3).
- To enable chronological sorting, it is advisable to start the name with a date, for example YYMMDD_Name or YYYYMMD_Name:
- 20181130_snake_case.txt
- 20181123CamelCase.txt
- Other examples of uniform naming:
- 20160512_climate_measurement1_original.jpg
- 20160522_climate_measurement1_MHU_extract.jpg
- 20160523_climate_measurement1_MHU_extract_edited_colour.jpg
- Automatically generated names (e.g. from the digital camera) should be avoided as they can lead to conflicts due to repetition. When deciding on the naming convention, do not disregard scalability: e.g. choosing a two-digit file number limits the data to 00-99 files.
- Not only for larger projects, but also for smaller research projects, it is worthwhile to record the chosen naming conventions in writing. In particular, explain chosen abbreviations in a data management plan or a readme file. It is often difficult to reconstruct these conventions years later.
- If you have an ID (see also Chapter 4) or study number, you should include it in order to be able to assign the data to a study and a researcher without any doubt (especially if several researchers are working on one project).
- Use abbreviations to indicate the type of data; e.g. questionnaire, experiment, excerpt, audio file, etc.


Fig. 7.2: Visualization camelCase
(Source: Lea Dietz)Fig. 7.3: Visualization snake_case
(Source: Lea Dietz)
Renaming:
Windows offers several alternatives for renaming existing file names. A simple renaming is possible by right-clicking and selecting the context point. Furthermore, after marking the respective file, the “F2” key on the keyboard can be used.
If you want to rename several files at the same time according to certain conventions, you need suitable software. This exists for most operating systems.
Windows
Mac
Linux
- GNOME Commander
- GPRename
- Unix: For Unix, the command “rename” can be helpful to find and rename files with regular expressions.
The following video by Christian Krippes (2018) briefly summarises the most important basic rules for structured and clear file naming: https://www.youtube.com/watch?v=M76gSb9Urmg

-
-
7.7 Databases and database systems
Suitable conventions for naming and storing files are already an important building block for efficient data organisation. However, if you work with a particularly large number of files or have special requirements for the structuring of your data, especially with regard to searchability, the use of database systems can be helpful. Here, not only are the files themselves sensibly structured, but they are also recorded in a database and provided with metadata (see Chapter 4). The metadata enable targeted filter and search functions. For example, an image database could quickly and conveniently display all images taken by a certain agency at a certain place at a certain time. Figure 7.4 illustrates the basic concepts of data organisation and their hierarchical relationship.
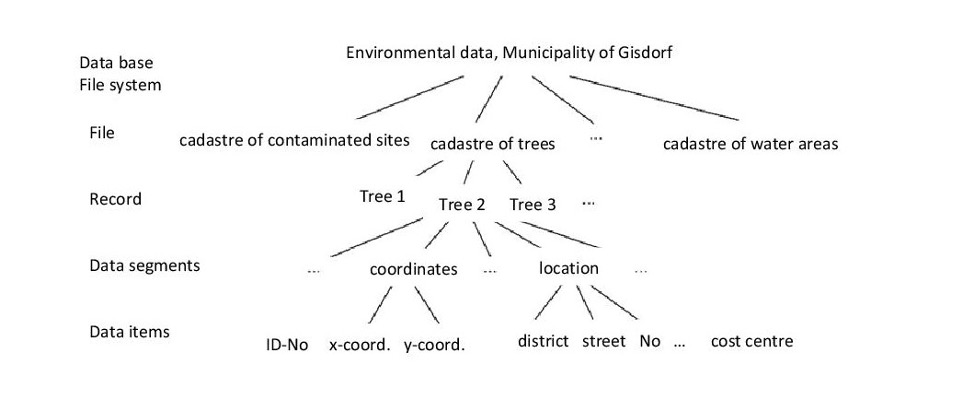
Fig. 7.4: Basic concepts of data organisation (De Lange 2006: 328).
At the lowest level of data organisation are data fields. These contain attribute values according to which they can be logically assigned to data segments (data groups). Several data segments build up a data record. Logically related data sets then form a file, while related files form file systems or databases.
However, databases are not sufficient for organising data for many user requirements; for example, some data must be stored several times in different locations in order to be able to use it for different applications. In addition, data protection can only be guaranteed with difficulty by assigning access rights. Therefore, database systems are needed. “A database system (DBS) consists of the database administration system or database management system (DBMS) and several databases (DB, also databases)” (De Lange 2006: 332). But what are databases and database management systems? A database consists of “multiple, interlinked data” (Herrmann 2018: 5), making it a collection of data whose data “are logically related” (Herrmann 2018: 5). The database is managed by the database management system; the latter is therefore software. Thus, database systems offer users efficient and bundled access to data and should fulfil the following requirements (De Lange 2006: 333):
- Evaluability of the data according to any characteristics
- Simple query options and evaluation, fast provision of data
- Allocation of different usage rights to the individual users
- Data and user programs are independent of each other, so the user only needs to know the logical data structures, while the DBS takes care of the organisational management
- No data duplication and data integrity
- Data security in the event of hardware failures and user programme errors
- Data protection against unauthorised access
- Flexibility with regard to new requirements
- Allowing multi-user access
- Compliance with uniform standards
The most common database management systems include Oracle, MySQL, Microsoft Access and SAP HANA.
-
-