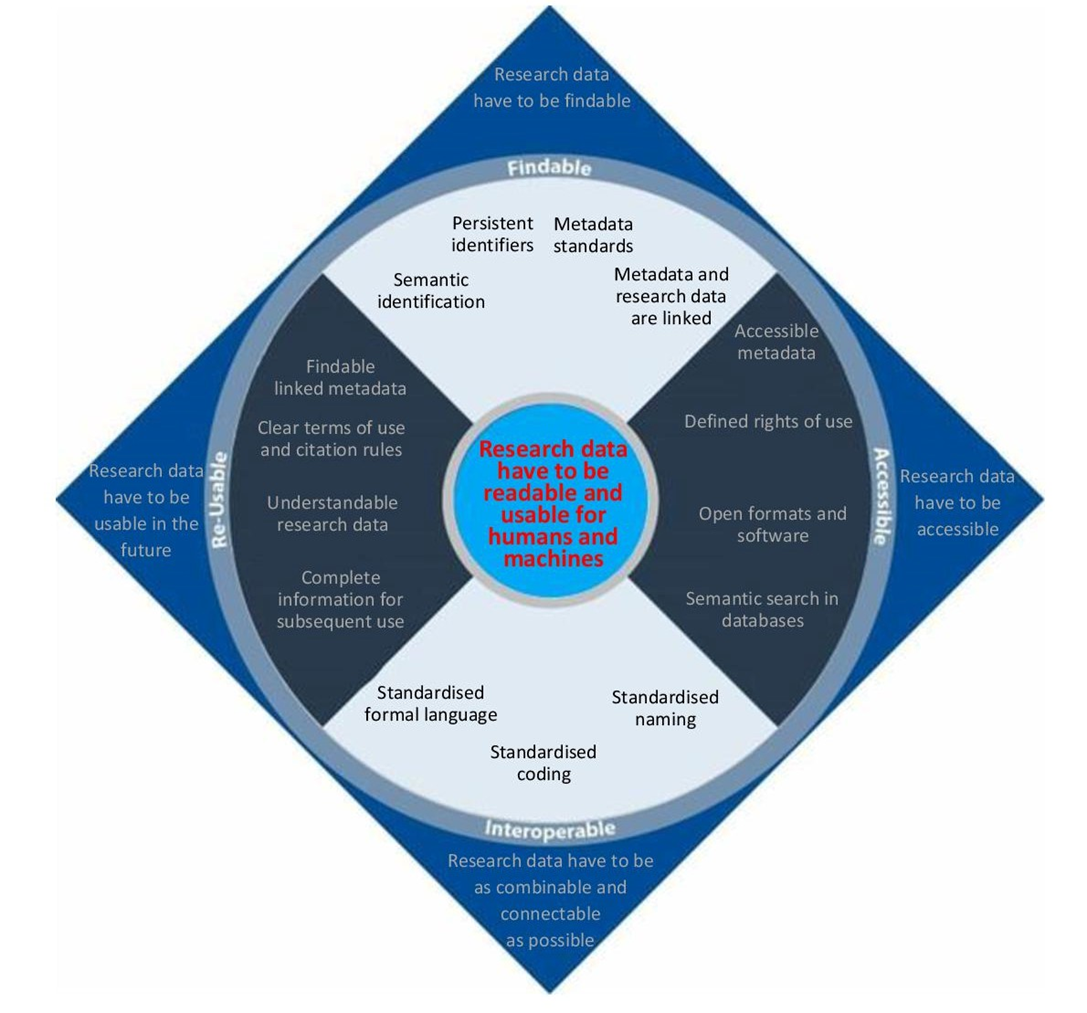
5.3 How do I prepare research data according to the FAIR principles?
In the following, aspects of preparing research data in accordance with the FAIR principles will be outlined on the basis of the above-mentioned properties and the original document with reference to the various steps in the research data cycle (planning, collection, archiving, etc.). Although the four properties are considered separately here, they require each other.
The following explanations serve only as a brief summary of the individual requirements of the FAIR principles. For a much more detailed overview of how you can implement them as a researcher, have a look at the TIB weblog for example.
Findability
Ensuring the findability of research data is crucial for the reusability of the data. An important step towards making data retrievable/findable is the assignment of so-called persistent identifiers, which globally ensure the unique and permanent identification of a digital resource. A frequently used form of such persistent identifiers is the DOI (Digital Object Identifier). This identifier must also be present in the metadata (see Chapter 4) and refer to the actual research data in order to be linked to it. It is also important to collect and document metadata that is as complete as possible, as well as all parameters of the actual research data, in order to improve retrievability. Finally, to make the data retrievable, the data must be fed into a searchable system that can be used by humans.
Accessibility
Once a user has found interesting research data via a search system, they are then facing the problem of accessing the data. In order to guarantee secure accessibility at all, the FAIR principles stipulate that standardised communication protocols (mainly http[s] and ftp) be used, which any browser can implement.
Data can either be published directly in research data journals or research data centres. Research data publications enable the publication of all research and metadata, not just a selection of research results as is known and common for peer-reviewed articles in journals.
When publishing research data, persistent metadata is very important. To be compliant with the FAIR principles, metadata of research data once published must continue to be available even if the research data may need to be withdrawn later. This condition should be met by all repositories, but check this anyway before publishing.
It should be noted, however, that not all research data is suitable for free publication. Great care must be taken with sensitive and personal data, as well as with the rights of other persons or an institution to the research data. Even if further use is still pending, for example for the application of a patent, all ambiguities must be resolved before publication. If the data is sensitive and therefore cannot be made freely available, it is sufficient, in order to comply with the FAIR principles, to provide a reference at some point in the metadata to whom to contact if one is interested in this data (e.g., e-mail address, telephone number, etc.). FAIR is therefore not necessarily synonymous with Open Access, even though it is desirable.
Interoperability
The term “interoperability” originally comes from IT system development and refers to the ability of systems to work with other systems that already exist or are planned for the future, as far as possible without restrictions. Transferred to research data, this means on the one hand that it should be possible to integrate data into other similar data without a major effort and on the other hand that the research data should be compatible with different systems for analysis, processing and archiving.
To ensure this, the FAIR principles propose the use of widely used formal languages and data models that are readable by both machine and humans. Examples of such languages include RDF, OWL, but also subject-specific controlled vocabularies (see Chapter 4.5) and thesauri.
Reusability
In order to enable a high degree of reusability of data by humans and machines, research data and the metadata related to it must be described so well that it can be replicated or reproduced and, in the best case also be applied to different settings. It helps to choose, if possible, reproducible settings from the outset and to provide the data with a large number of unique and relevant attributes that should, among other things, answer the following questions for other users in order to be able to draw conclusions about the generation of the data:
- For what purpose or area of application was the data collected or generated?
- When was the data collected?
- Is the data based on own or third-party data?
- Who collected the data and under what conditions (e.g. laboratory equipment)?
- Which software and software versions were used?
- Which version of the data is available, if more than one?
- What were fixed baseline parameters in the survey?
- Is it raw data or already processed data?
- Are all variables used either explained somewhere or self-explanatory?
Furthermore, the data must contain information on the licence status, i.e., there must be information on which data use licence the corresponding data fall under (see Chapter 9). In the age of Open Science, Open Access licences for one's own data are desirable and are also required by many funders. The best-known OA licences include Creative Commons and MIT, both of which also comply with the FAIR principles. To ensure that the data can also be used by others and that it is possible to draw accurate conclusions about the origin, the metadata should also contain standardised information about the citation.