2 The life cycle of research data
Bölüm anahatları
-
processing time: 9 minutes, 45 seconds
-
2.2 The research data life cycle
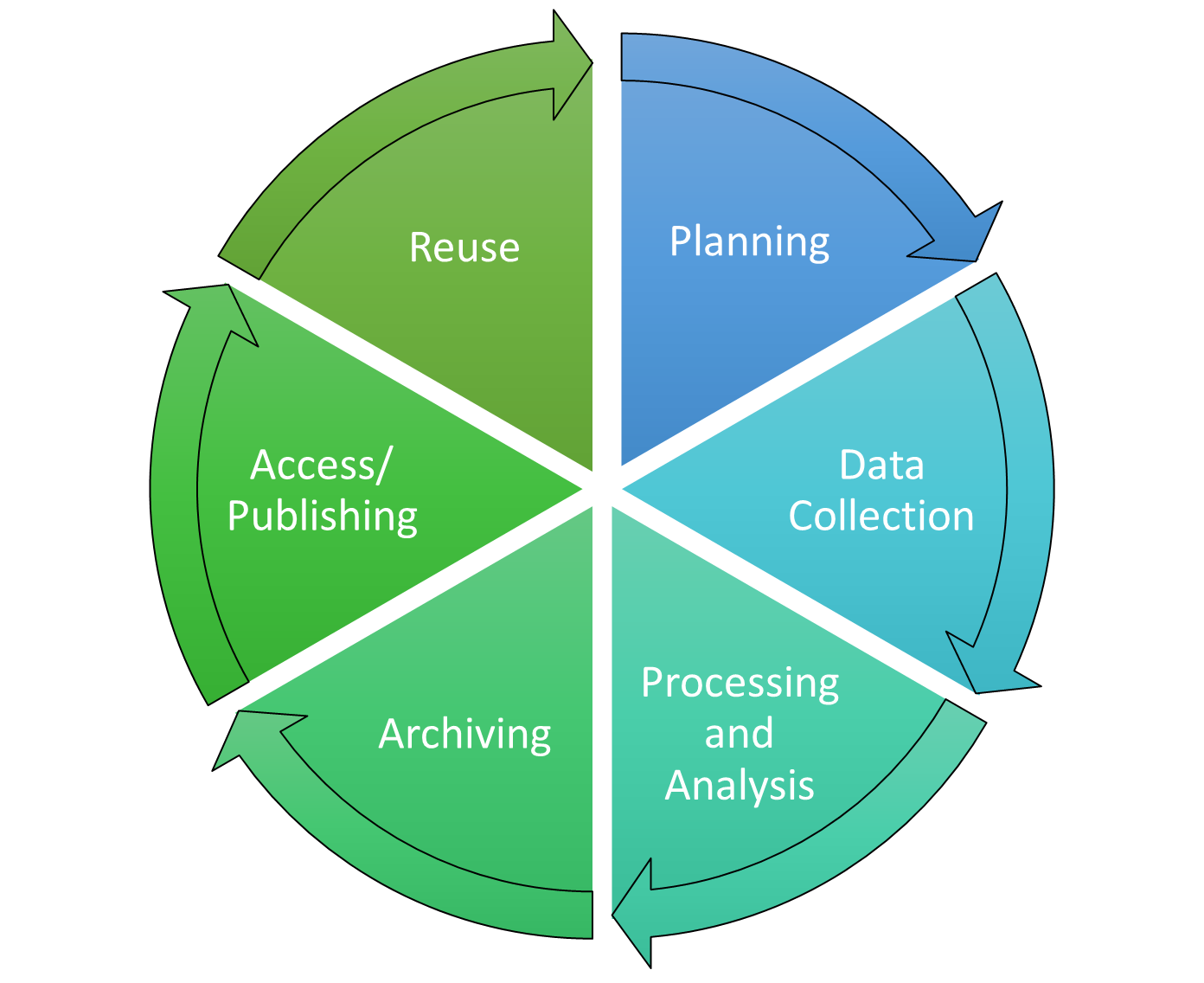
Fig. 2.1: The research data lifecycle (based on the DCC Curation Lifecycle Model)
The research data life cycle is a visualisation of the research process that focuses specifically on the role of data. It shows that a professional approach to research data involves more than just collection and analysis. As a researcher, it is worthwhile to always consider all phases when making decisions and to find out at an early stage which tools and options are available to optimise your practice in dealing with research data.
-
2.3 Individual steps in the research data life cycle
The following section takes a closer look at the individual phases and describes what you can do in detail with regard to research data management.
1. Planning
“By failing to plan, you are preparing to fail.” - Benjamin Franklin
Only with good planning good results can be achieved. This requires careful consideration, consultation, and research. With regard to research data management, many research funders already require a so-called data management plan when the application is submitted (see Chapter 3). However, even without explicit requirements, it is worthwhile to set out in writing in advance exactly how the data are to be handled. This creates commitment and uniformity (especially in projects with several participants) and can serve as a reference work, checklist, and documentation.
Overall, the following aspects may be relevant for planning:
- Determine study design
- Assemble project team and clarify roles
- Set up schedule
- Plan data management (formats, storage locations, file naming, collaborative platforms, etc.)
- Review existing literature and data
- Re-use of existing data, if applicable
- Clarify authorship and data ownership
- Coordinate access possibilities and conditions
2. Survey
Data collection can sometimes account for a considerable part of the research work. In addition, mistakes made in this phase persist throughout the entire research process and, in the worst case, lead to incorrect results without being noticed. This makes it all the more important to take special care during the survey. In addition to the actual data, this concerns above all the documentation of the research carried out as well as a (preferably standardised) collection of metadata. Metadata has to be well structured and offers further information about your data, which is described in more detail in Chapter 4.
Overall, the data collection should cover the following aspects:
- Carrying out the experiments, observations, measurements, simulations, etc.
- Generation of digital raw data (e.g. by digitising or transcribing)
- Storage of the data in a uniform format
- Backup and management of data
- Metadata collection and creation
- Documentation of the data collection
3. Processing / Analysis
You know best how to analyse your data. It is important that you apply and document the standards and methods that are common in your field.
For yourself and especially in collaboration with others, it is important to have a system of file naming, versioning, and data organisation. Collaboration platforms offer support. For more information, see Chapters 6 and 7.
Overall, you can consider the following aspects when processing and analysing data:
- Check, validate, clean data (quality assurance)
- Derive, aggregate, harmonise data
- Use subject-specific standards (e.g. with regard to methods and file formats)
- Prepare the use of the data in scientific publications
- Document data processing (for later understanding)
- Use cooperation platforms for data exchange with (specialist) colleagues
- Run analyses
- Interpret data
4. Archiving
In the Code for “Safeguarding Good Research Practice” (2019) of the German Research Foundation, guideline 17 describes that “research data (generally raw data) […] are generally archived in an accessible an identifiable manner for a period of ten years”. This serves scientific quality assurance and enables the long-term verifiability of scientific findings. In addition, the data can be reused by other scientists if necessary.
However, in order to enable actual reuse, a number of conditions must be met:
- Comprehensibility
- Durable, preferably non-proprietary (i.e. free and open source) file formats.
- durable storage media
- Findability
It therefore makes sense to use professional archiving services. The Frankfurt UAS offers the following (free) service for this purpose: Institutional Research Data Repository
You will learn what else you should consider with regard to archiving your research data in Chapter 8.
5. Access / Publication
In addition to (text) publication in scientific journals, the data on which publications are based are also increasingly in demand. Many research funders and journals now require explicit data publication. This can provide additional quality assurance and, if other researchers work with your data, you gain reputation through citations.
There are basically three ways of publishing research data (Biernacka et al., 2018):
- As a supplement to a scientific article (= data supplement)
- As an independent publication in a repository (= long-term storage location for data)
- As an article in a Data Journal
a. These are (usually) peer-reviewed papers that present and describe datasets with a high value for reuse in more detail. The data itself is usually published in a research data repository.
The portal re3data is suitable for searching for an appropriate repository. Its important that the chosen repository meets the FAIR principles for research data. Further information on this can be found in Chapter 5.
6. Subsequent use
When sharing and publishing research data, make sure that it can actually be re-used. This opens up a wide range of possibilities:
- Further research with existing data (secondary data analysis)
- Verification of results (replication, quality assurance)
- Linkage with other data (record linkage)
- Use in practical teaching
The prerequisite for subsequent use is licensing. Creative Commons licences are often used for this. In the spirit of Open Science, these should be chosen as openly as possible.
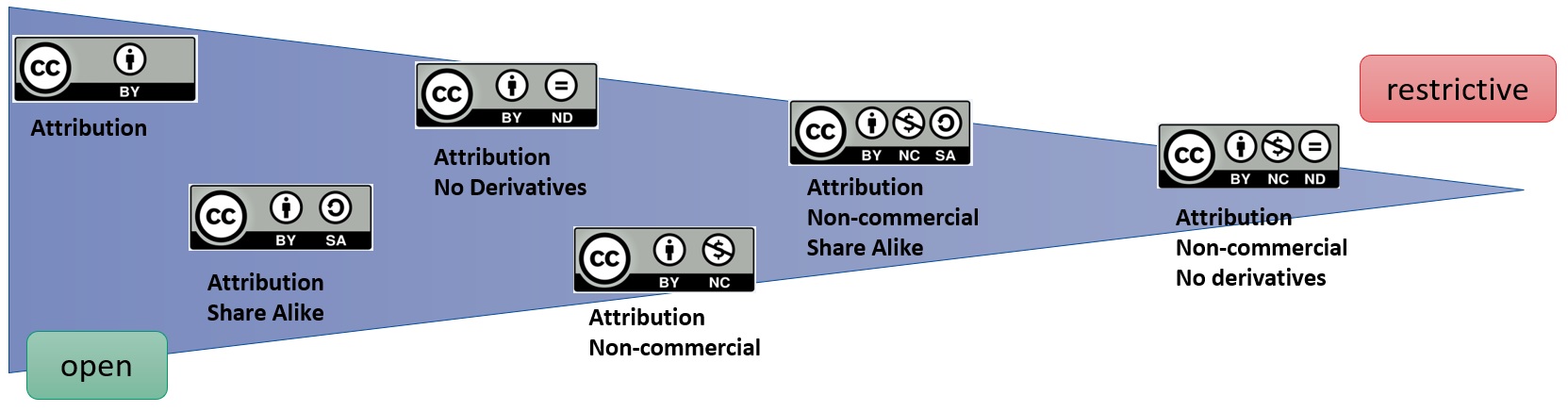
Fig. 2.2. Possible uses of data under different Creative Commons licences (Translated from: Apel et al. 2017, p. 57)
Furthermore, it is important that the data is of good quality (complete, accurate, cleaned, without gaps) and sufficiently documented. File formats also play an important role. These should be as widespread and non-proprietary as possible. If necessary, it may also make sense to store the data twice (once in the original format and once in an open format). An overview of suitable file for-mats can be found, for example, at forschungsdaten.info.
To ensure that data can be found and cited correctly in the long term, the use of persistent identifiers (PID) is a good idea. They permanently refer to a specific content (e. g. data set) and are thus ideally suited for citations. A web link can change, a PID always remains the same. There are two types of PIDs:
- Identifiers for digital objects, e.g.
- DOI = Digital Object Identifier
- URN = Uniform Resource Name
- Identifier for persons (clear scientific identity), e.g.
- ORCID = Open Researcher Contributor Identification
- ResearcherID
Repositories and journals automatically assign corresponding identifiers for the data/contributions submitted. If you also have a personal identifier (such as ORCID), your work can be automatically linked to your profile.
-
-